NEWS
2019.05.27
2019年5月24日、CadenceはAIチップベンチャーのThinCI社による採用事例を発表した。
CadenceによるとThinCIはAIチップの開発で「Cadence Verification Suite」を採用。同スイートには以下のシミュレータ、エミュレータ、プロトタイピング・ボードが含まれており、ThinCIはこれらツールを用いる事でシミュレーションの実行時間を短縮、ハードウェア・ソフトウェア協調検証や最終アプリケーションでの動作証明も行い、製品開発のスケジュールを数か月短縮することができたとしている。また、カバレッジ検証、フォーマル検証、検証プロジェクトの管理などもCadenceのツールで実施したという。
・Xcelium™ Parallel Logic Simulation Platform
・Palladium® Z1 Enterprise Emulation Platform
・Protium™ S1 FPGA-Based Prototyping Platform
ThinCIはディープラーニング推論向けのプロセッサを開発する北米のベンチャーで、デンソー子会社のNSITEXEと「データフロープロセッサー(DFP)」の共同開発を行なっている。
ThinCIにはデンソー、未来創生ファンド(トヨタも出資)、ダイムラー他、複数のベンチャーキャピタルが出資しており、その累計調達額は昨年時点で8500万ドルに達している。
2019.05.24
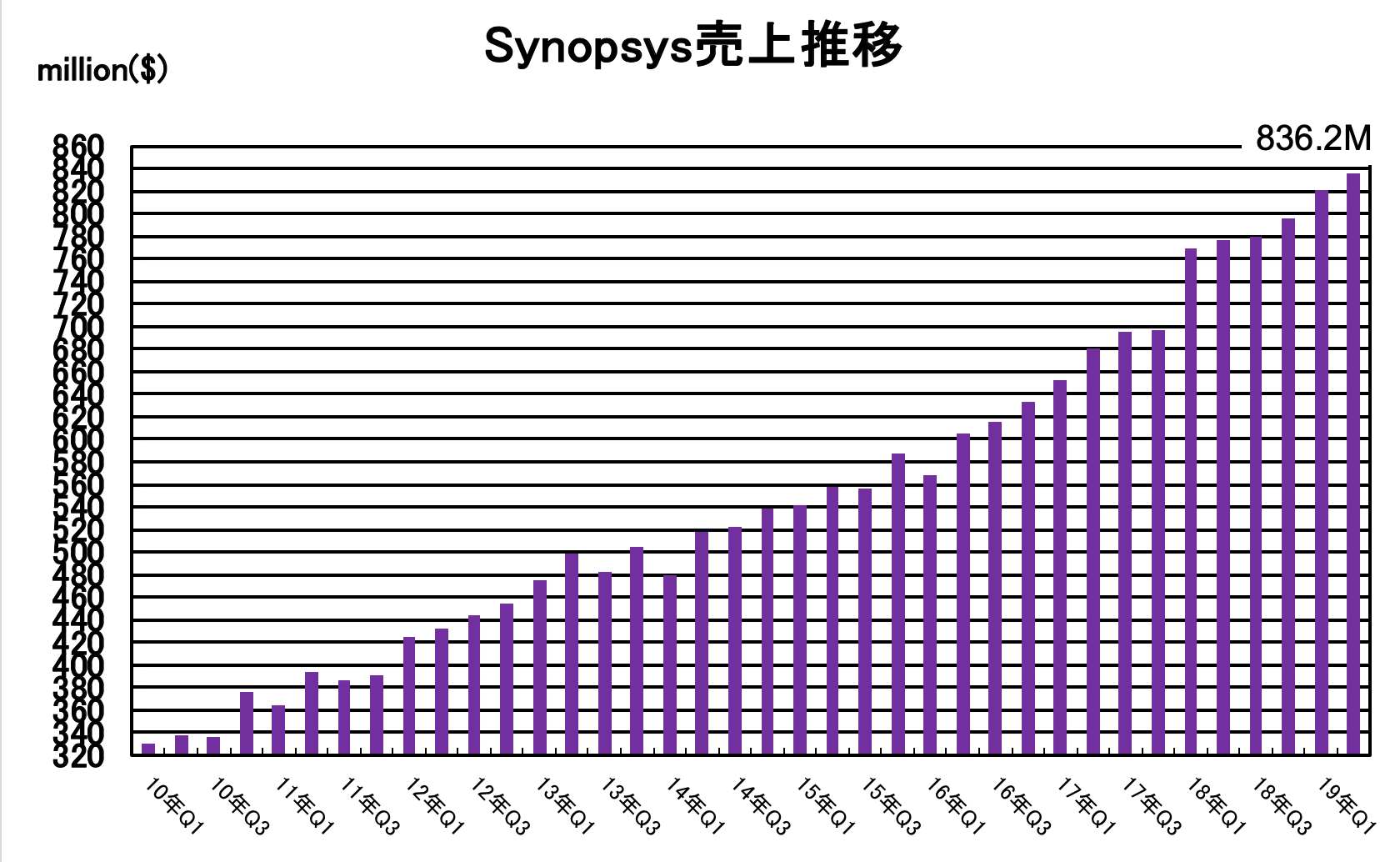
2019年5月22日、Synopsysは、2019会計年度第2四半期(19年2-4月)の四半期決算を報告した。
発表によるとSynopsysの2019会計年度Q2の売上は、前年同時期比約7.6%増、前Q1比約2%増の8億3620万ドルでまたも同社の四半期売上記録を更新した。四半期売上記録の更新はこれで6四半期連続。営業利益は前年比約15.3%増の1億1820万ドルだった。(※GAAP基準による会計結果)
主力のEDAおよびIP事業だけでなく、ソフトウェア開発向け製品事業の売上も好調だったようだ。
SynopsysはこのQ2において、論理合成ツールの新製品「Design Compiler NXT」、フィジカル検証ツールの新製品「IC Validator NXT」、DFTツールの新製品「TestMAX」ファミリなどを相次いで市場投入している。
Synopsysは2019会計年度Q3(19年5月-7月)の売上を8億1000万-5000万ドルと予測している。
2019.05.24
2019年5月16日、タイミング制約に関する包括的なEDAソリューションを提供する米Excelliconは、デンソー子会社のIPベンダNSITEXEによる採用事例を発表した。
Excelliconは、EDA製品としてSDC自動生成およびマネジメントツール「ConMan」とSDCサインオフツール「ConCert」を提供しており、タイミング制約周りに特化したソリューションがワールドワイドで支持されている。今回、NSITEXEは論理合成、配置配線、スタティックタイミング解析に使用されるタイミング制約フローの自動化し、不要なデザインサイクルを無くすためにExcelliconのSDCソリューションを採用した。
日本国内ではRenesas、Socionext、MegachipsなどもExcelliconのツールを利用している。
2019.05.24
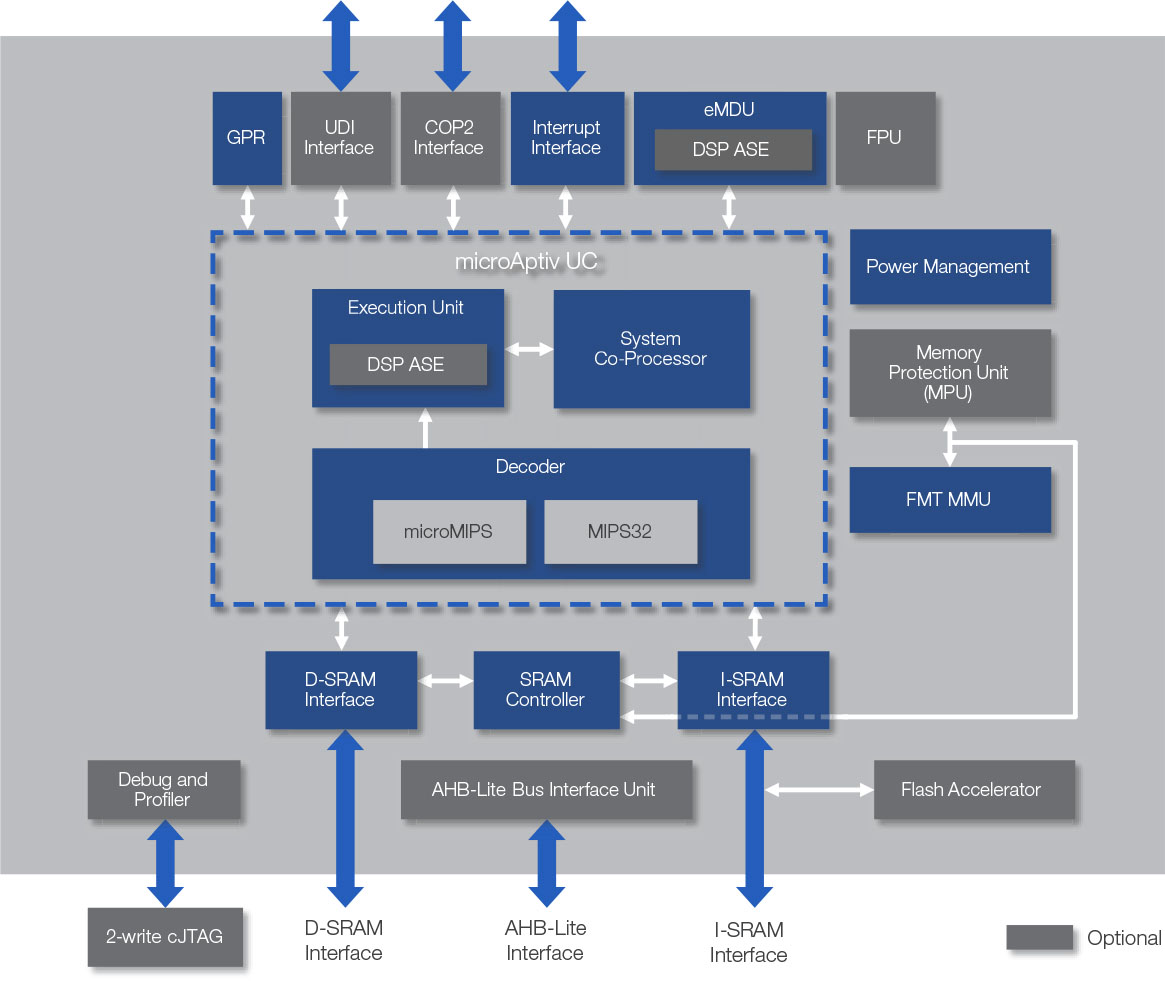
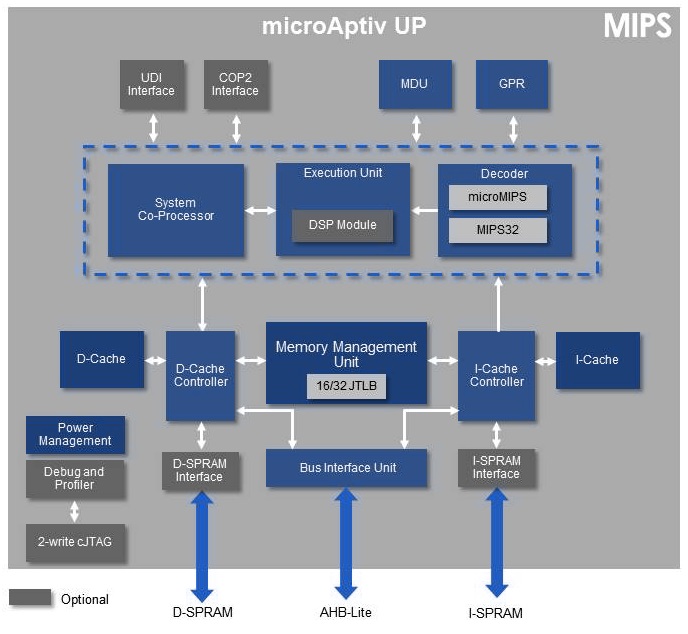
2019年5月13日、Wave Computingは、「MIPS Open program」にMIPS32 microAptiv Core 2品種を追加したことを発表した。
今回「MIPS Open program」に追加された「MIPS32 microAptiv™」コアは、MIPSコアの中で最も小型で低電力なCPUの1つで、マイクロコントローラや自動車、IoT、ホームネットワーキング機器などのエントリーレベルの組み込みアプリケーション向け。
今回下記の2品種のコアが公開され、Verilog-RTLコード、コンフィギュレーション・ツール、検証スイート、ドキュメントが無償でダウンロード可能となった。
・microAptiv MCU core
アプリケーション固有の機能とリアルタイム性能を重視して開発されたMCU 向けコア
・microAptiv MPU core
キャッシュ・コントローラとMMUを含む、LinuxなどのOSを実行する組み込みシステム向けコア
microAptiv MCU coreのブロック図
microAptiv MPU coreのブロック図
公開されたRTLコードはライセンス料やロイヤリティ無しで商用利用可能。
2019.05.23
2019年5月21日、デザインサービスおよびIP販売を手掛ける米Innovative Logicは、同社の子会社が手掛けるUSB IPをSiFiveが買収したことを発表した。
発表によるとSiFiveは、USB IPの買収と合わせて同IPを開発していたInnovative Logic Indiaの従業員の大半を雇用したという事で、事実上Innovative Logic Indiaを買収した形となる。
Innovative Logic Indiaは、シリコン実績のある認定済みUSB IPの開発と実装で高い評価を得ており、次世代USB 3.xのIP開発および先端プロセスへの実装も手がけている。
SiFiveのCEOは、Innovative Logic IndiaのチームをSiFiveファミリーに迎え入れ、IPロードマップの拡大に期待するとコメント。具体的にUSB IPをどう販売していくかについては言及していないが、IPの単体販売の他に、同社のRISC-V IPを搭載したSoCプラットフォームに組み込んで販売する形も考えられる。
2019.05.22
2019年5月21日、SoC組み込み型FPGAを手掛けるAchronixは、新しいFPGAファミリ「Speedster7t」を発表した。
発表によると「Speedster7t」は、TSMC 7nm FinFETプロセスで製造されるスタンドアロンのFPGAで、機械学習および広帯域ネットワーキング・アプリケーション用に最適化された新しいアーキテクチャーをベースとしている。同アーキテクチャーの特徴は以下の通り。
・新しい2Dネットワークオンチップ(NoC)
データトラフィックをFPGAファブリック全体に水平方向と垂直方向に分散。NoCの各行または各列は、各方向に512Gbps相当の速度でデータを転送できる。(各行/列は2x256ビット,単方向のAXIチャネルとして実装されている)
・高密度の新しい機械学習プロセッサ(MLP)を搭載
MLPは最大32個のMACを備えたコンフィギュラブルな演算ブロック。4から24ビットの整数型とBfloat16を含む様々な浮動小数点モードをサポート。MLPブロックとエンベデッド・メモリブロックの緊密な結合によりFPGA配線に伴う遅延を無くし、機械学習アルゴリズムを最大周波数750MHz、61.4TOPSで実行できる。※最大構成でMAC数40,960個(int8)の場合
・最大8個のGDDR6コントローラ、4Tb/s以上のメモリ帯域幅を提供。
HBMベースのFPGAと同等のメモリ帯域幅を数分の1のコストで提供可能。
・PCIe Gen5 2x16, Ethernet 32レーン, 8x400G
・6入力LUT 最大 260万個
・オンチップ・メモリ最大 300Mb
※画像は全てAchronix web上のデータ
Achronixは、FPGAのプログラマビリティとASICの配線構造およびコンピューティング・エンジンを融合させた新たな「Speedster7t」のアーキテクチャーは、既存のFPGAの上を行く「FPGA+」クラスのテクノロジを生み出すとしている。
「Speedster7t」のSampleチップと評価用ボードは、2019年第4四半期に発売される予定。
2019.05.22
2019年5月21日、グラフィックスIPを手掛けるデジタルメディアプロフェッショナル(以下DMP)は、エッジAIプロセッサIPコアの新製品「ZIA™ DV720」の発売を発表した。
新製品「ZIA™ DV720」は、エッジ向けのディープラーニング推論に特化した既存の「ZIA™ DV700」の後継品で、アーキテクチャの改善により更なる小型化と性能向上を実現した。
具体的には、MAC(積和演算器)を最適化し、これまでソフトウェアで処理させていたINT8bit/FP16bitコンバータをハード化、IPコア内部のパイプラインも効率化した。これにより16nmプロセスのASIC搭載時に1GHz以上の動作周波数を実現。XilinxのFPGA「Zynq® UltraScale+™ MPSoC」搭載時はコア周波数420MHzで動作可能。「ZIA™ DV700」と比較して60%の小型化と3.2倍以上の高性能化を実現しており、FPGAでもASICに近い性能を達成することができるという。
「ZIA™ DV720」のSDK/Toolは、「ZIA™ DV700」との後方互換で、Caffe、Keras、TensorFlowといった汎用AIフレームワークに対応している。
DMPは6月3日に「ZIA™ DV720」を実装したFPGAボード「ZIA™ C3 」の新バージョンをリリースする予定。
2019.05.22
2019年5月21日、グラフィックスIPを手掛けるデジタルメディアプロフェッショナル(以下DMP)は、エッジAIプロセッサIPコアの新製品「ZIA™ DV720」の発売を発表した。
新製品「ZIA™ DV720」は、エッジ向けのディープラーニング推論に特化した既存の「ZIA™ DV700」の後継品で、アーキテクチャの改善により更なる小型化と性能向上を実現した。
具体的には、MAC(積和演算器)を最適化し、これまでソフトウェアで処理させていたINT8bit/FP16bitコンバータをハード化、IPコア内部のパイプラインも効率化した。これにより16nmプロセスのASIC搭載時に1GHz以上の動作周波数を実現。XilinxのFPGA「Zynq® UltraScale+™ MPSoC」搭載時はコア周波数420MHzで動作可能。「ZIA™ DV700」と比較して60%の小型化と3.2倍以上の高性能化を実現しており、FPGAでもASICに近い性能を達成することができるという。
「ZIA™ DV720」のSDK/Toolは、「ZIA™ DV700」との後方互換で、Caffe、Keras、TensorFlowといった汎用AIフレームワークに対応している。
DMPは6月3日に「ZIA™ DV720」を実装したFPGAボード「ZIA™ C3 」の新バージョンをリリースする予定。
2019.05.21
2019年5月20日、SynopsysとKudanはマシンビジョン向けソリューションに関する両社の協業について発表した。
Kudanは人工知覚(Artificial Perception)に関する研究開発をベースに、各種SLAM(Simultaneous Localisation and Mapping)ソリューションを提供するテック系ベンチャーで、昨年末に東証マザーズに上場している。
VIDEO
今回SynopsysとKudanの両社は、高効率/高精度なマシンビジョンSoCの実現に向けて協業。具体的には、Kudanの提供するSLAMアルゴリズムをSynopsysのEmbedded Visionプロセッサ「ARC EV6x」向けに最適化し、ベクターDSPとCNNエンジンを備える「ARC EV6x」のリッチなハードウェア・リソースと組み合わせる事で、他のソリューションよりも圧倒的に低電力かつ省メモリなSLAMアプリケーションの実行環境を実現する。
Synopsysの「ARC EV6x」は既に一般リリースされており、「ARC EV6x」に最適化されたSLAMアルゴリズム「KudanSLAM」は2019年下期に入手可能になる予定。
ここ最近、にわかにSLAMアルゴリズムのDSP実装に関する話題が多い。時同じくして5月20日にCEVAは、同社の「CEVA-XM」DSPおよび「NeuPro AI」プロセッサをターゲットに、SLAMアルゴリズムの実装を効率化するための「CEVA-SLAM SDK」を発表 。つい先日も、CadenceがSLAMアルゴリズム用の拡張命令とSLAMアルゴリズム用の演算ライブラリを追加した新型DSP「Tensilica Vision Q7」を発表している。(関連ニュース )
2019.05.21
2019年4月29日、eeNews Analogの記事:
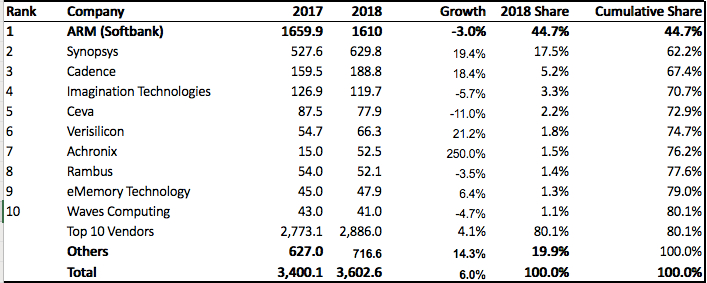
調査会社IPnestのレポートによると、2018年半導体IP市場の売上ランキングは下記図の通り。
※Source: IPnest april/2019
市場シェア4割以上を握るリーダーARMの売上は前年比3%減の16.1億ドルで、2年ぶりに市場シェアを落とした。
成長率2桁以上の大きな成長を見せたのはSynopsys, Cadence, VeriSilicon, Achronixの4社。
SoC組み込み型FPGAコアを手掛ける新興企業Achronixは、前年比250%増と売上が3倍以上に伸びた。
市場全体としては、2018年は前年比6%増の成長に留まった。2017年の成長率は11.7%だった。
IPnestは、市場において汎用IPからアプリケーション固有のIPへとシフトする動きがあることを指摘。特にCPUやDSPにおいて顕著で、Synopsys,Cadence 対 ARM, Andesという構図に当てはまるとする。
また、他のデジタルIPやインターコネクトIPの売上が増加している一方で、プロセッサとフィジカルIPの売上は全体の割合として下落しており、ARMの他にImagination TechnologiesやWave computing(MIPS)も売上を落としている。その背景には、RISC-Vベースプロセッサや各種マシンラーニング向けIP、特殊なアーキテクチャの新型IPなどの活況があるとしている。
2019.05.17
2019年5月16日、Mentor Graphicsは、島津製作所によるPCB設計環境「Xpedition™」の採用事例を発表した。
発表によると島津製作所は、MentorのPCB設計環境「Xpedition™」を全社標準ツールとして採用。構想設計から回路図入力、プリント基板の設計から製造までの電子設計における全プロセスを一気通貫するフローとして、「Xpedition™」の導入を決めた。
島津製作所は「Xpedition™」の標準化に至るモチベーションとして、製造プロセスとの連携をはじめとする設計プロセスの大幅な改善を挙げている。なお島津製作所が採用したXpeditionフローには、 「HyperLynx™」高速解析ツール、PCB製造向けのソリューション「Valor™ NPI/Valor™ MSS」などMentorの提供する周辺技術も含まれている。
2019.05.17
2019年5月16日、Mentor Graphicsは、島津製作所によるPCB設計環境「Xpedition™」の採用事例を発表した。
発表によると島津製作所は、MentorのPCB設計環境「Xpedition™」を全社標準ツールとして採用。構想設計から回路図入力、プリント基板の設計から製造までの電子設計における全プロセスを一気通貫するフローとして、「Xpedition™」の導入を決めた。
島津製作所は「Xpedition™」の標準化に至るモチベーションとして、製造プロセスとの連携をはじめとする設計プロセスの大幅な改善を挙げている。なお島津製作所が採用したXpeditionフローには、 「HyperLynx™」高速解析ツール、PCB製造向けのソリューション「Valor™ NPI/Valor™ MSS」などMentorの提供する周辺技術も含まれている。
2019.05.16
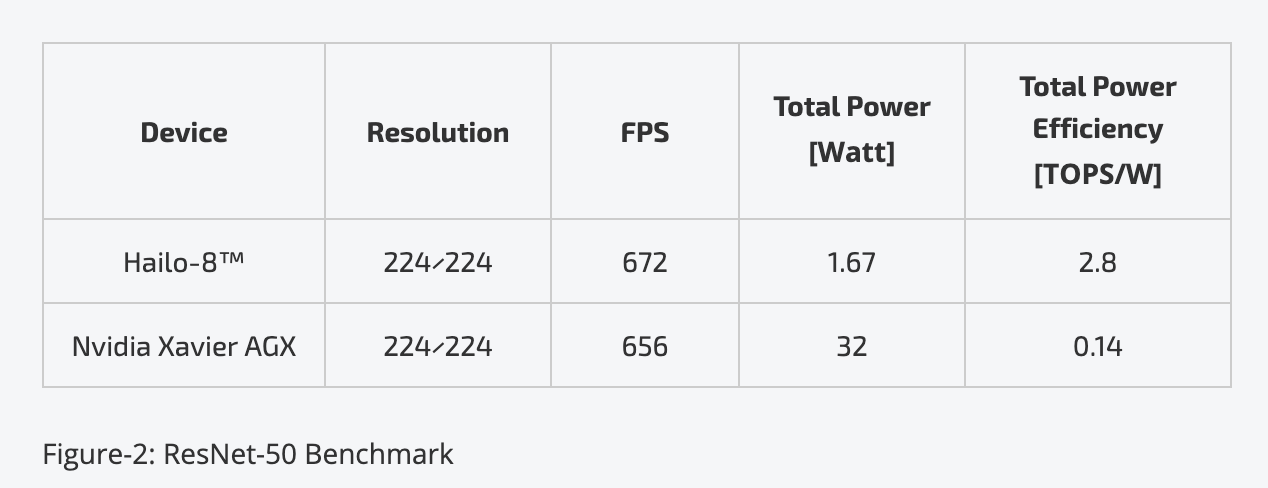
2019年5月15日、イスラエルのAIチップ・スタートアップHailo Technologiesは、ディープラーニング・プロセッサ「Hailo-8」のリリースを発表した。
Hailoのディープラーニング・プロセッサ「Hailo-8」は、業界トップクラスの性能を謳うもので、Halioによると「Hailo-8」を用いる事でこれまでクラウド上でしか実行できなかった高度なディープラーニング・アプリケーションをエッジデバイスで実行できるようになるという話。
詳細は不明だが「Hailo-8」のアーキテクチャは、メモリ、制御、およびコンピューティングという既存のコンピュータ・アーキテクチャの柱を見直し、ニューラルネットワークの特性を踏まえて構築されており、1セント硬貨より小さな「Hailo-8」は、他の全てのエッジ・プロセッサよりもはるかに優れた面積あたりの性能および電力効率を実現するとしている。
実際にHailoの示すベンチマークデータによると、「Hailo-8」は同等のCNNタスクを「Nvidia Xavier AGX」の20分の1の消費電力で実行できるという事だ。
なお、Hailoは既に先行顧客に「Hailo-8」のサンプルを出荷中で、自動車分野を中心に様々な業界のパートナーとチップの試作を進めているという。
VIDEO
2019.05.16
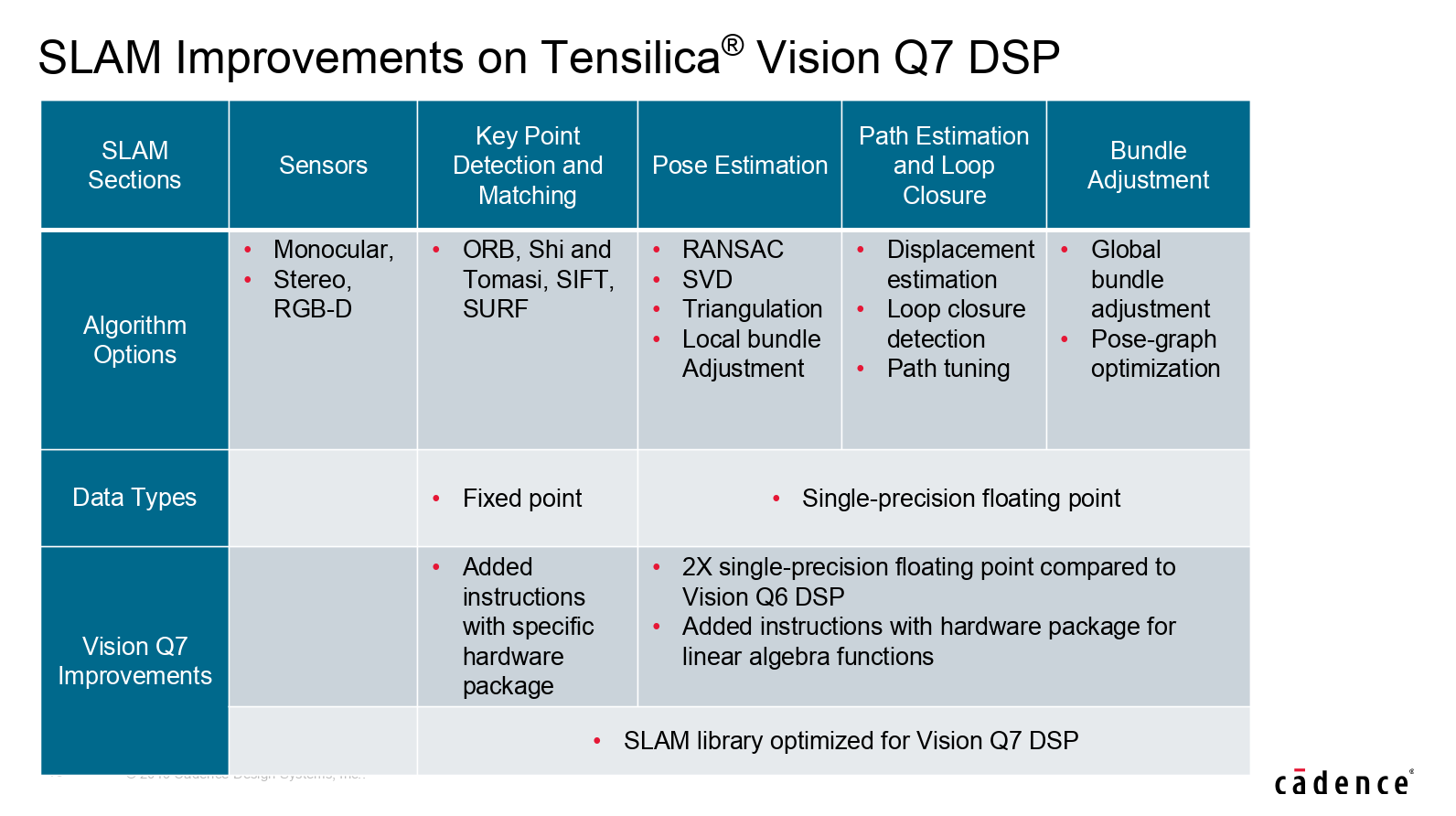
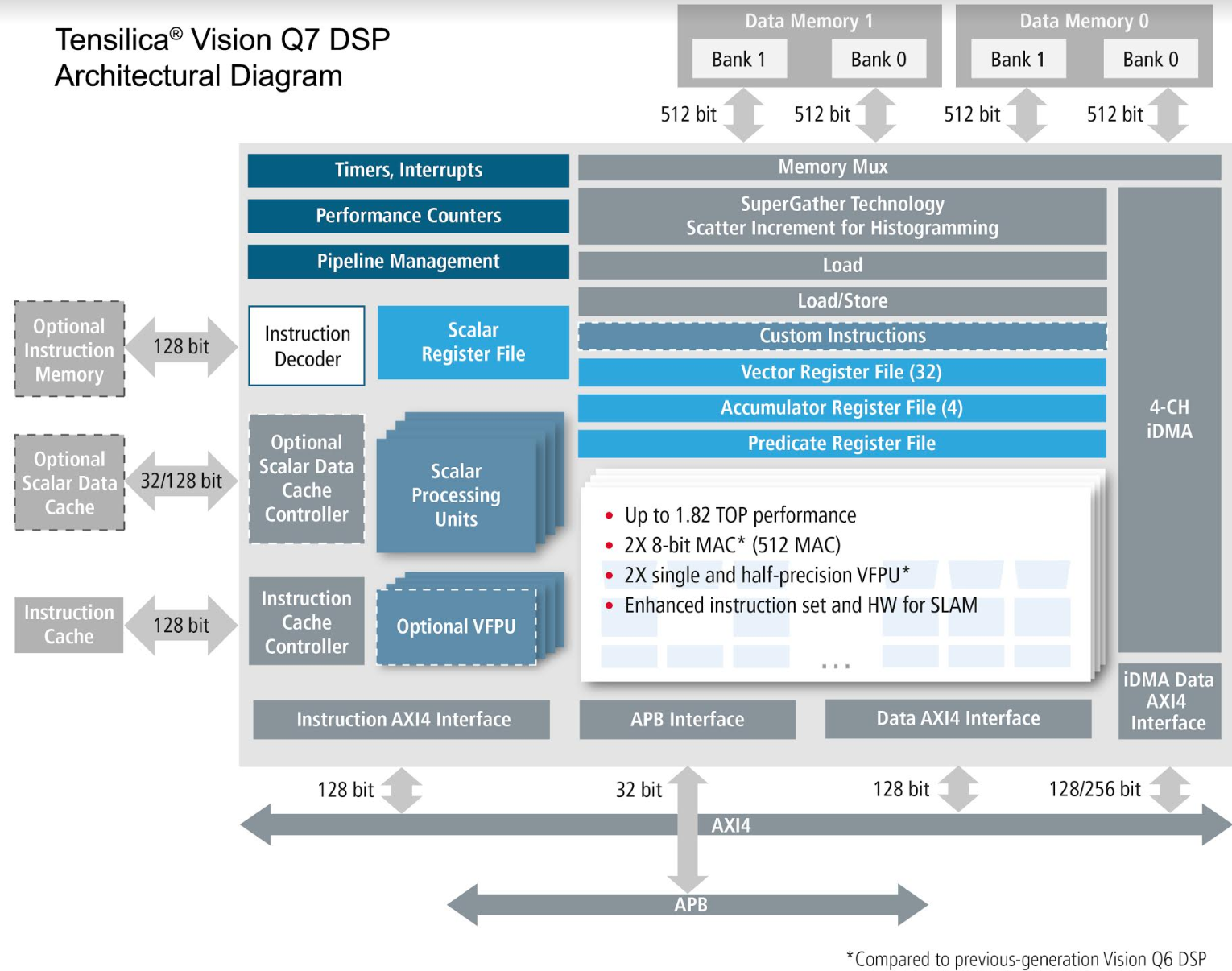
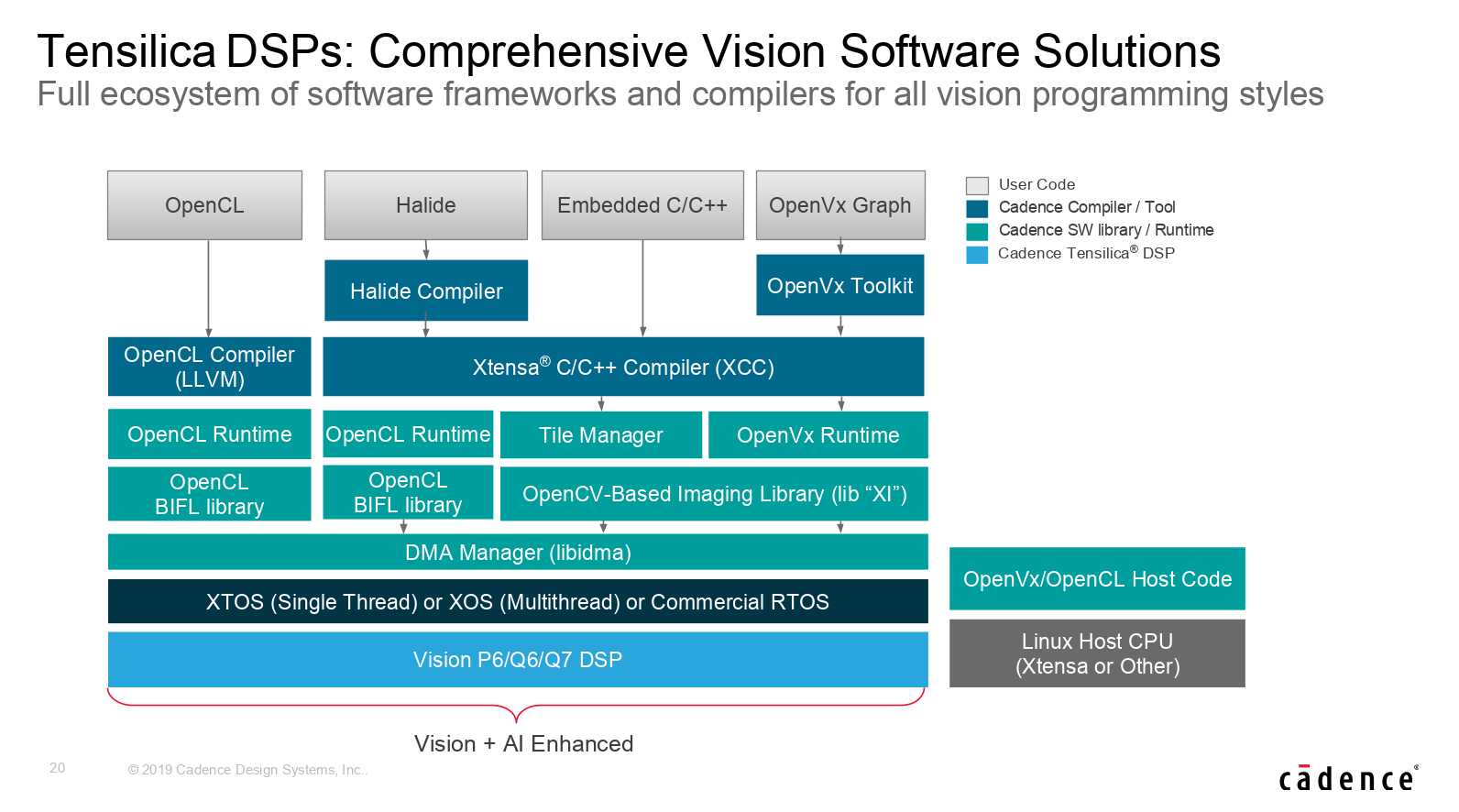
2019年5月16日、CadenceはDSPコアの新製品「Tensilica Vision Q7」を発表した。
発表によると「Tensilica Vision Q7」は、既存の「Vision Q6」の後継にあたる第7世代目の製品で、Vision及びAIアプリケーションを扱うエッジ向けSoCを主なターゲットとしている。当然ながら「Vision Q7」は「Vision Q6」よりも性能向上が図られており、演算性能はQ6と同じ面積で最大2倍、最大1.82TOPSのパフォーマンスを誇る。
「Vision Q7」の 性能向上の背景には、MAC及び単精度/半精度浮動小数点数ユニットの倍増など演算リソースの増強が挙げられるが、特筆すべきはSLAM(Simultaneous Localization and Mapping)アルゴリズムに特化した最適化が施されている点で、SLAMアルゴリズム用の拡張命令が追加されたほか、SLAMアルゴリズム用の演算ライブラリも新たに用意された。この「Vision Q7」に最適化されたSLAMライブラリを利用する事で高い処理性能を容易に実現できるという。なお、面積を増やす事なく性能向上を実現できているのは、ハードとして設計を改善/最適化したところも大きいという話だ。
「Vision Q7」は、Vision/AIアプリケーションの要求性能に応じて、マルチコア化により柔軟に対応可能。推論パフォーマンスを要求される場合は推論専用の「DNA100」と併用することもできる。また、「Vision Q6」の後方互換であるため、既存のソフトウェアを簡単に移植できる。
ソフトウェア開発環境としては、AIアプリケーション向けにCaffe, TensorFlow/TensorFlow Lite, Android Neural Networks API(NNAPI)をサポート。Visionsアプリケーションに向けては、最近OpenCL及びHalideにも対応可能となった。また「Vision Q7」はツール環境も含めてISO 26262の認証を受けているという。
※画像は全てCadence提供のデータ
Cadenceによると「Vision Q7」は既に先行顧客向けにリリース済みで、一般リリースは2019年Q2からの予定。
※日本ケイデンス・デザイン・システムズ社
2019.05.15
2019年5月13日、各種EDAソリューション及び設計IPを手掛けるSilvacoは、Samsung FoundryとのIP販売に関する提携について発表した。
発表によるとSilvacoは、Samsung Foundryとの提携により同社の生産実績のある各種IPを販売。IPに関するライセンス供与やサポートなどもSilvacoを通じて行われる。
Silvacoは以前から組み込みプロセッサ、バスなどの各種設計IPを販売しているが、同社のIPラインナップにSamsung FoundryのIP資産が加わることになる。
販売されるSamsung IPの最初のハードウェアIP製品は、14nmプロセス向けの製品で、今後は11nm、10nm、8nmといった先端プロセスや28nmプロセス向け製品も拡充される予定。
IPにはソフトウェアIPも含まれているようで、今年6月より販売が開始される。
2019.05.14
2019年5月13日、Imagination Technologiesは、SiFiveのDesignShareエコシステムへの参加を発表した。
SiFiveのDesignShareは、同社の提供するRISC-VベースCPUを搭載するSoCプラットフォーム「Freedom」を核としたエコシステムで様々なIPベンダが加盟している。SiFiveの顧客はIPベンダとの契約を必要とせずに、SoCプラットフォーム「Freedom」に各種IPを統合したSoCのプロトタイプを入手することが可能。「Freedom」をベースとしたSoCを開発する際に、SiFiveを通じて様々なIPをワンストップで利用できるというシステムがDesignShareである。
今回、Imagination TechnologiesがDesignShareエコシステムに参加したことにより、SiFiveの顧客はImagination Technologiesの「PowerVR GPU」と「NNA IPコア(ニューラルネットワークアクセラレータ)」にアクセス可能となる。
なお、カスタムSoCのプロトタイプはSiFiveが構築。チップを量産する段階でIPコアの利用料を支払うが、その窓口もSiFiveが一括して対応する。
2019.05.14
2019年5月9日、IC Insightsのレポート:
IC Insightsのレポートによると、2018年のアナログICベンダの売上トップは昨年同様TIで売上100億ドルの大台を突破。前年比9%の成長で市場シェア18%を確保した。
ランキング2位はInfineonに代わりAnalog Devicesが浮上。同社の売上には買収したLiner Technologyの売上も含まれているが、売上額は首位TIの約半分。
成長率が最も高かったのはST Microelectronicsで前年比26%増の32億ドルの売上を記録。同社のアナログIC製品の主なターゲットは、モーションコントロール(モータドライバICおよび高電圧ドライバIC)、オートメーション(インテリジェントパワースイッチ)、エネルギー管理(電力線通信IC)アプリケーションなど。
IC Insightsによると、アナログIC市場は上位10社が市場の60%を占めているという。
2019.05.13
2019年5月9日、TOPPERSプロジェクトは、組込みソフトウェアプラットフォーム「TOPPERS BASE PLATFORM」がRISC-Vに対応した事を発表した。
発表によるとTOPPERSプロジェクトは、米SiFive社のRISC-Vプロセッサ搭載ボード「HiFive1」ボードにTOPPERS/ASPカーネル(Release 1.9.3)をポーティングするとともに、それを核とした組込みソフトウェアプラットフォーム「TOPPERS BASE PLATFORM(RV)V0.1.0」 を開発した。
TOPPERS BASE PLATFORM(RV)V0.1.0の構成(発表資料掲載図)
TOPPERS/ASPカーネルをポーティングしたのは、「HiFive1」上のSoC「FE310-G000」に搭載されるSiFive製の32ビット RISC-Vベース・プロセッサ「RV32IMAC」で、同TOPPERS/ASPカーネルはオープンソース・ソフトとして一般公開される。「TOPPERS BASE PLATFORM」は、STマイクロエレクトロニクスのSTM32マイコン搭載ボードと、IntelのCyclone V SoCを搭載したボードをターゲットとした2種類のプラットフォームが既にリリースされており、今回開発された「TOPPERS BASE PLATFORM(RV)V0.1.0」 は、TOPPERSプロジェクトの会員向けに配布が開始されている。同プラットフォームを利用することで、Arduino互換の「HiFive1」ボード上で動くTOPPERSベースの組込みアプリケーションを簡単に開発することができるようになる。
2019.05.11
2019年5月10日、ヤマハ発動機はディジタルメディアプロフェッショナルとの業務資本提携を発表した。
発表によるとヤマハは、自社製品の自動化・自律化に向けたAI開発力の強化を主な目的としてDMPと提携。DMPが発行する第三者割当による新株式を引き受け、DMPの筆頭株主となる。一部メディアの報道によると株式の引き受け額は約15億円という話だ。
ヤマハは今後、DMPのディープラーニング、画像処理・画像認識技術を低速度自動・自律運転システム、農業用ロボット、各種モビリティの先進安全技術などの開発に活用していく計画。
2019.05.10
2019年5月8日、高性能FPGAを手掛けるEFINIXとSamsungは両社の協業を発表した。
発表によると両社は、Samsungの10nm FinFETプロセス向けの「Quantum™ eFPGA」と呼ぶFPGA製品の開発で協業。「Quantum™ eFPGA」の詳細は不明だが、既存のFPGAよりも高性能、少面積を実現するという、EFINIXのプログラマブル・アーキテクチャ「Quantum」をベースとしたSoC組み込み型FPGAと推測される。
SoC組み込み型のFPGAコアを提供するIPベンダとしては、AchronixやFlex Logix Technologiesなどが挙げられるが、両社はTSMCのプロセスを主なターゲットとしており、Samsungプロセス向けの製品は提供していない。
2019.05.09
2019年5月7日、Cadenceは、同社の「Tensilica Vision DSP」がPreferred NetworksのChainerモデルをサポートした事を発表した。
発表によると、ニューラルネットワークのアクセラレータとして利用されているCadenceの「Tensilica Vision DSP Q6、P6、C5」が、Preferred Networksのディープラーニング・フレームワーク「Chainer」で実装された学習済みニューラルネットワーク・モデルをサポート。Cadenceの用意するDSP向けの環境「Tensilica Neural Network Compiler」を用いてChainerモデルをCコードに変換しDSP上で動作させることが可能となった。CadenceによるとChainerモデルのポーティングは自動化されており、モデルの変換などの手作業は不要だという。
エッジでの推論をターゲットとするニューラルネットワークのアクセラレータIPは、各IPベンダから様々な製品がリリースされているが、ディープラーニング・フレームワークとしては、Googleの「TensorFlow」、UC Berkeleyの「Caffe/Caffe2」等のサポートが一般的で、「Chainer」のサポートは珍しい。
2019.05.09
今年3月、当サイトで2019年世界半導体市場の予測が悲観的になりつつある事を報じたが(関連ニュース )、ここに来て大手調査会社による市場予測の下方修正が相次いでいる。
まずDIGITIMESの記事によると、調査会社大手のIHSは、2019年の市場予測を前年比マイナス7.4%に下方修正した。同社は昨年12月の時点では2.9%のプラス成長と予測していた。
IHSによると、7.4%の減少は11%の減少を記録した2009年以降で最大。メモリに加えASSPも売上が急落しており、半導体業界は過去10年間で最悪の年に向かっているとIHSは指摘している。
もう1社、半導体業界専門の調査会社IC Insightsも2019年の市場予測をマイナス9%に下方修正した。同社は年初の時点で1.6%のプラス成長と予測していた。
IC Insightsによると、1984年第1四半期から2019年第1四半期までの計141四半期において、四半期ごとの売上推移で10%以上の市場下落が起こったのはわずか7回。2018年Q4から2019年Q1にかけて起こった17.6%の市場減少は過去4番目に大きなものだという。
2019.05.08
2019年5月8日、Cadenceは第三世代目の製品となるフォーマル検証ツール「Cadence® JasperGold® Formal Verification Platform」(以下、新型JasperGold」を発表した。
発表によると新型「JasperGold」は、機械学習技術の活用によりフォーマル検証のコア技術を改良。具体的には「Smart Proof Technology」と呼ぶ、機械学習を用いた証明アルゴリズムと証明エンジンの選択・設定機能を使い、より高速な証明を可能にする。Cadenceは「Smart Proof Technology」によって、証明の実行速度が最大4倍に高速化できるとしており、実際に同ツールを試用したSTMicroelectronicsの担当者は、証明の実行時間が即座に平均2倍高速化できたとコメントしている。機械学習技術は、リグレッション・テストの実行の最適化においても活用されており、Cadenceによると実行速度を最大6倍高速化できるという。
またCadenceによると、新型「JasperGold」は1年前のバージョンと比較してコンパイル規模が2倍になり、メモリ使用量を平均50%削減することが可能に。更にクラウド上で利用できる並列コンパイル技術によって、扱えるデザイン規模を効果的に増やすことができるという事だ。
前出のSTMicroelectronicsの担当者によると、新型「JasperGold」を試用した結果、検証効率を劇的に改善できたという話で、証明の実行速度の高速化に加え、リグレッション・テストの高速化(5倍高速化)、収束しないプロパティの削減(50%以上削減)も確認できたという。
2019.05.07
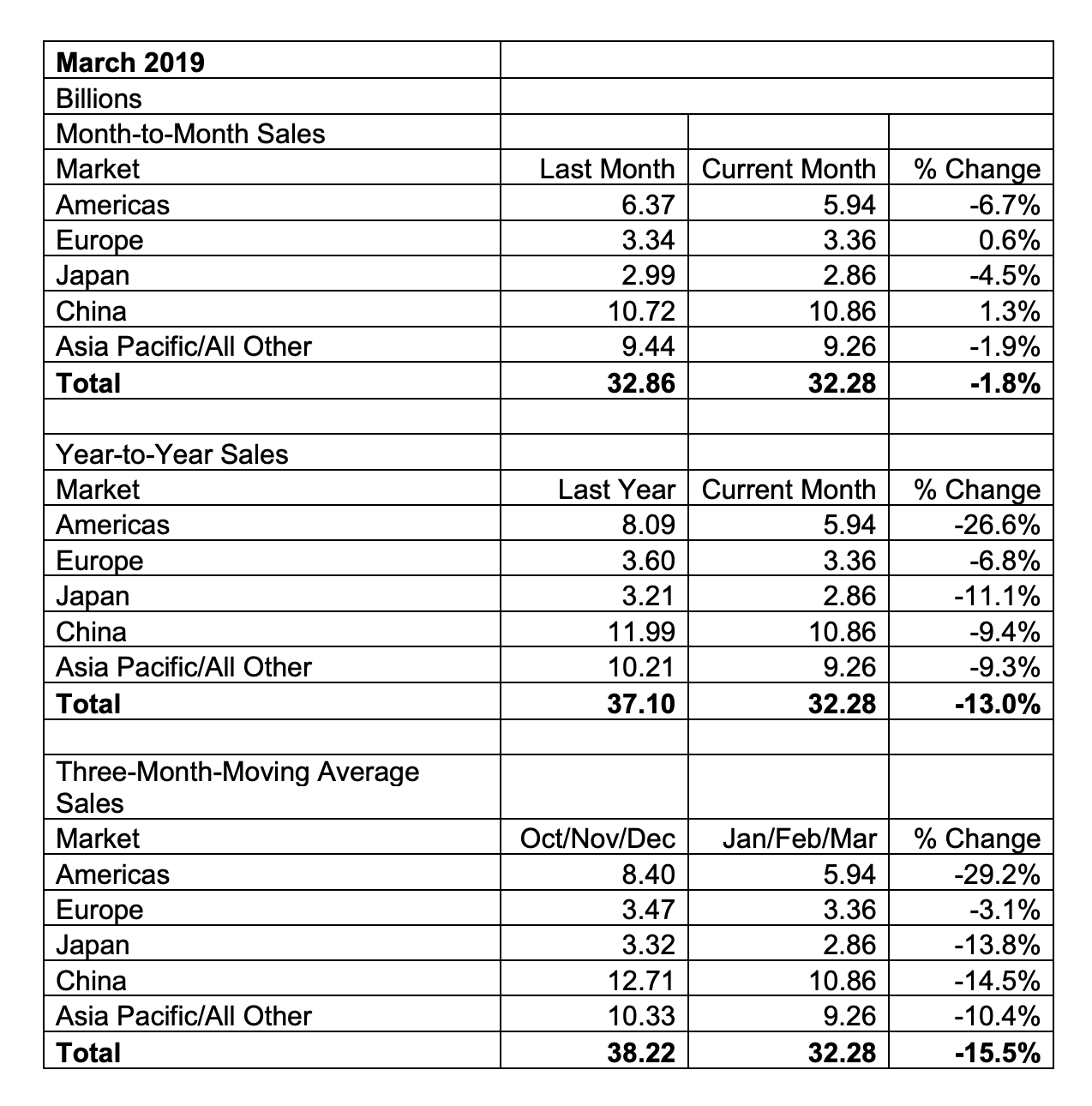
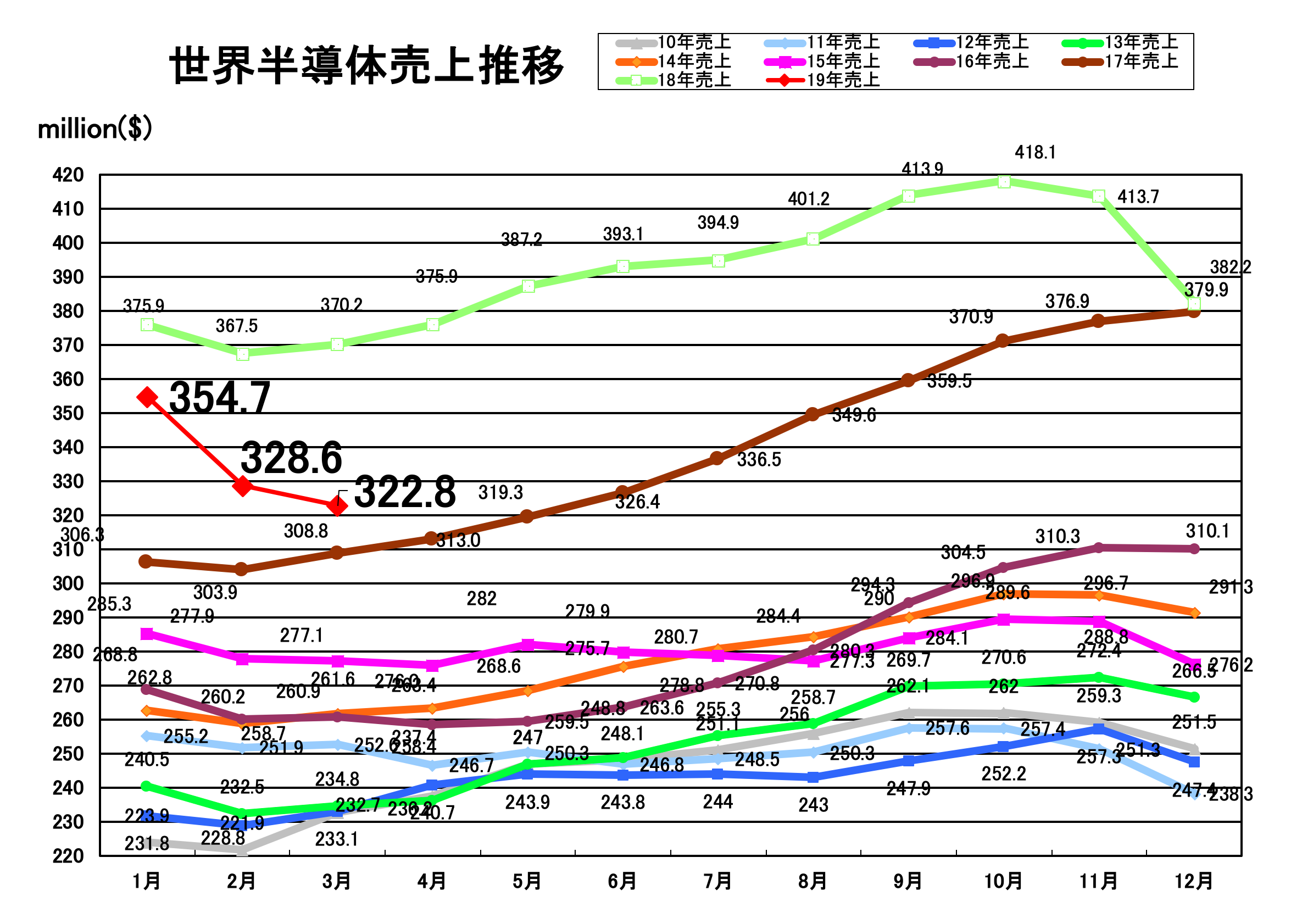
2019年4月29日、米SIA(Semiconductor Industry Association)は、2019年3月の世界半導体売上(3ヶ月移動平均)を発表した。
SIAの報告によると2019年3月の世界半導体売上は、前年同月比13%減、前月比1.8%減の322.8億ドルという結果だった。これで2019年に入り1-3月は全て前年実績割れ。四半期売上で見ると2019年Q1(1-3月)は2018年Q4の実績に対してマイナス15.5%となっている。売上の減少は2018年11月以降5ヶ月連続。
2019年3月の売上を地域別で見ると全ての地域で前年実績を下回った。最も売上の落ち込みがひどい北米市場は、2月よりも更に売上が減少し、前年比26.6%減の59.4億ドルだった。
日本市場の3月の売上は前月比4.5%減、前年比11.1%減の28.6億ドルで、北米市場に次いで売上の減少率が高かった。売上を円ベースで換算すると前年比約6.5%減の約3180億円となる。
このままのペースで売上が落ち続けると、4月または5月の時点で2年前の2017年の実績を割り込む可能性が高い。
2019.04.26
2019年4月24日、AIアクセラレーター・チップを手掛けるベンチャー米Gyrfalcon Technologyは、AI推論アクセラレータIPのライセンス・モデルを発表した。
Gyrfalcon Technologyは2017年にシリコンバレーで設立されたAIチップベンチャーで、エッジ向けおよびデータセンター向けのAIチップを既に製品化している。今回発表したのは既にチップ化されたAIアクセラレータのIP販売でカスタムSoCの開発向けに下記の2品種のIPをライセンス供給する。
・Lightspeeur 2803:16.8TOPS/1W以下
・Lightspeeur 2801:2.8TOPS/300mW
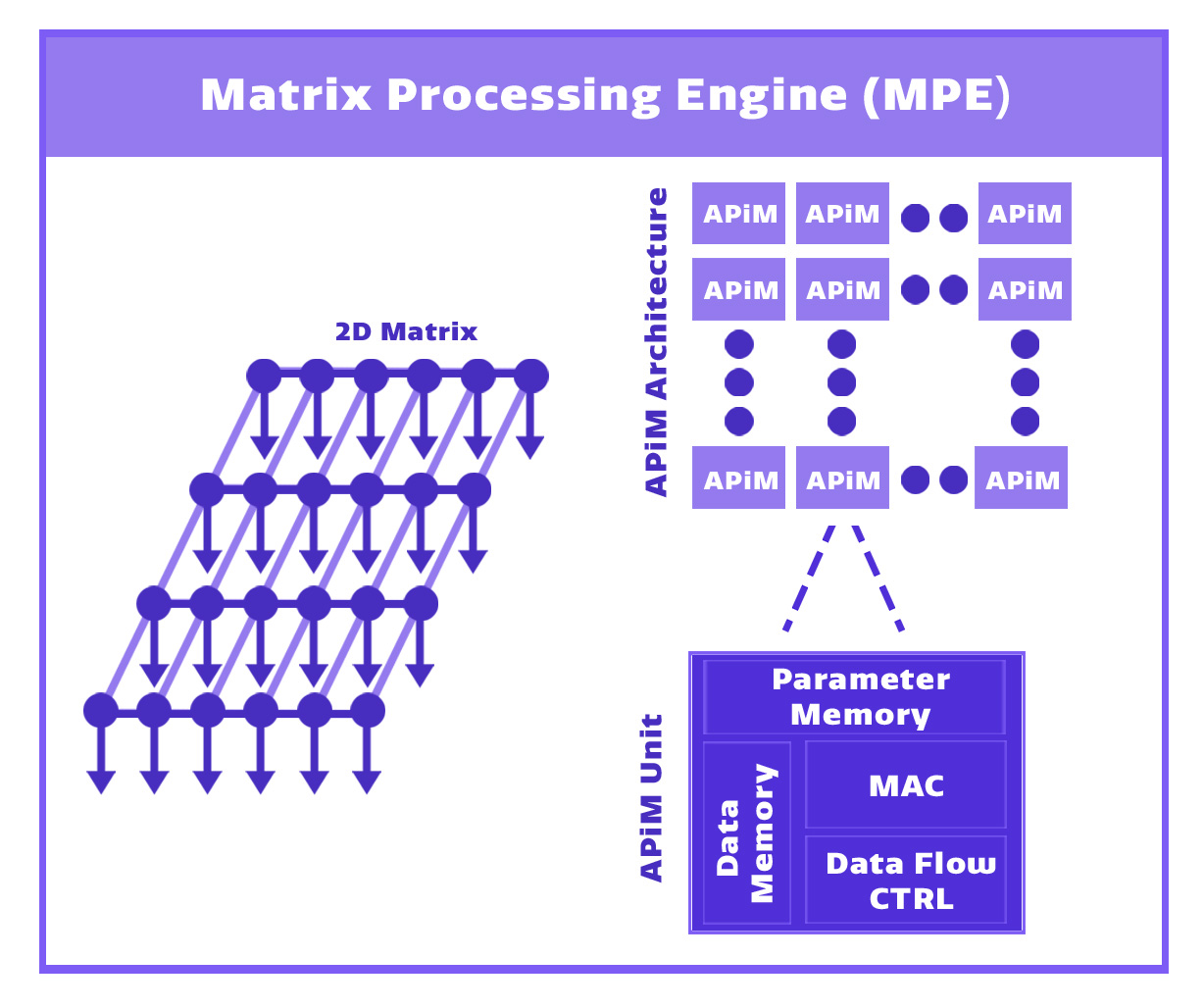
Gyrfalcon TechnologyのAI推論アクセラレータは、独自の特許技術に基づく「Matrix Processing Engine (MPE) 」によりCNN処理を超高速かつ超低消費電力で実行可能。同エンジンは「AI Processing in Memory (APiM) 」と呼ばれる処理ブロックにより構成されている。
Gyrfalcon Technologyによると既に同社の顧客により3種類のAIアクセラレータ・チップが製造されているとの事。日本ではファブレス半導体メーカーSocionextがGyrfalcon Technologyとの提携を発表しており、同社のAIアクセラレータを用いたマルチコア・プロセッサ「SynQuacer SC2A11」を製造している。
2019.04.26
2019年4月25日、Xilinxは、高性能で低レイテンシのネットワーク・ソリューションを提供する米Solarflare社の買収を発表した。
買収に関する取引条件などの詳細は明らかにされていないが、XilinxによるSolarflareの買収はXilinxの2020会計年Q2(19年7-9月)に完了する見込み。
Solarflareの主なターゲットはFintech企業やデータセンターで超低レイテンシのネットワーク技術を強みとしている。Xilinxは自社のデバイスとSolarflareの超低レイテンシNICおよびOnloadアプリケーション・アクセラレーション・ソフトを組み合わせ、新しい「SmartNIC」ソリューションを実現するとしており、データセンター向けビジネスの更なる拡張を目指す。
今回の買収は3月に発表されたNVIDIAによるMellanox買収(関連ニュース )と同じ構図で、Xilinxもデータセンター向けのソリューションとして広帯域幅で低遅延のネットワーク技術を必要としていた。XilinxはMellanoxの買収も検討していたと噂されていたが、2年前から戦略的投資家として組んでいたSolarflareの買収を決定した。
なお今回の買収はXilinxの2019年度会計報告と同時に発表された。Xilinxの2019年度の売上は前年比24%増の30億6000万ドルで過去最高を記録した。
2019.04.25
2019年4月16日、すでに買収によりIntelの傘下となっているOmnitekは、IntelのFPGA向けのディープラーニング・コアを発表した。
DPU(Deep Learning Processing Unit)と呼ばれるOmnitekのディープラーニング・コアは、IntelのミッドレンジFPGA「Arria 10 GX」に最適化されており、「Arria 10 GX 1150」でCNNモデル「VGG-16」を実行した場合、FP32精度で135 GOPS/Wを達成。Omnitekは、このワット当たりの処理性能をミッドレンジのプログラマブル・デバイスとして世界トップクラスとしている。また、同コアは低精度で演算した後に精度を回復するための再トレーニングを行うという、固定小数点演算と浮動小数点演算を組み合わせたアプローチをとる事で、精度を損なう事なく非常に高い演算密度を達成できるという。
OmnitekのDPUはIntelのFPGA「Stratix 10 GX」にも拡張可能なプログラマブルなコアで、TensorFlowをサポートしており、C/C++またはPythonでプログラム可能。GoogLeNet, ResNet-50, VGG-16といった標準的なCNNモデルと同様に独自のカスタムモデルも実装可能で、特にFPGA設計の専門知識は必要ない。(※RNN, MLPなどには今後対応予定。フレームワークとしてはCaffeもサポートされる予定。)
Omnitekによると、DPUは英オックスフォード大学との共同研究プログラムから生まれた技術を応用して開発されたもので、ビデオやイメージング分野のAI対応アプリケーションのコスト削減に特に力を発揮。DPUを補完する各種ライブラリも豊富に用意されているとの事。
OmnitekはこれまでXilinxのFPGA向けに各種コアを開発していたが、先日Intelによる買収が発表された。※関連ニュース
2019.04.24
2019年4月22日、Cadenceは、2019会計年度第1四半期(2019年1-3月)の売上を報告した。
Cadenceの2019年Q1売上は、前年比約11.6%増、前期Q4比約1.2%増の5億7700万ドルで10四半期連続で四半期売上記録を更新した。営業利益は前年比約65%増の1億2100万ドルだった。(※GAAP基準による会計結果)
Cadenceはこの4月にシステム解析領域に事業を拡大し、最初の製品となる電磁界シミュレータ「Cadence Clarity 3D Solver」を発表している。プレスリリース
Cadenceは2019年Q2の売上を5億7500万-8500万ドル、2019年の総売上を23億500万-3500万ドルと予測している。
2019.04.24
2019年4月23日、ElectronicsWeekly.comの記事:
Huaxintongは、Armベースのサーバーチップ開発を目的に3年前に設立された中国貴州省とQualcommの合弁企業。
出資比率はQualcomm45%、貴州省55%で、2018年8月までに5億7000万ドルを投資した。
Qualcommは最近Armベースのサーバーチップの開発を断念。Huaxintongのクローズはこれを受けての事で4月末までに閉鎖されると報じられている。
Huaxintongの離脱により、残るArmベース・サーバーチップ開発企業は、Caviumを買収したMarvellとAmpere Computingのみ。
2019.04.23
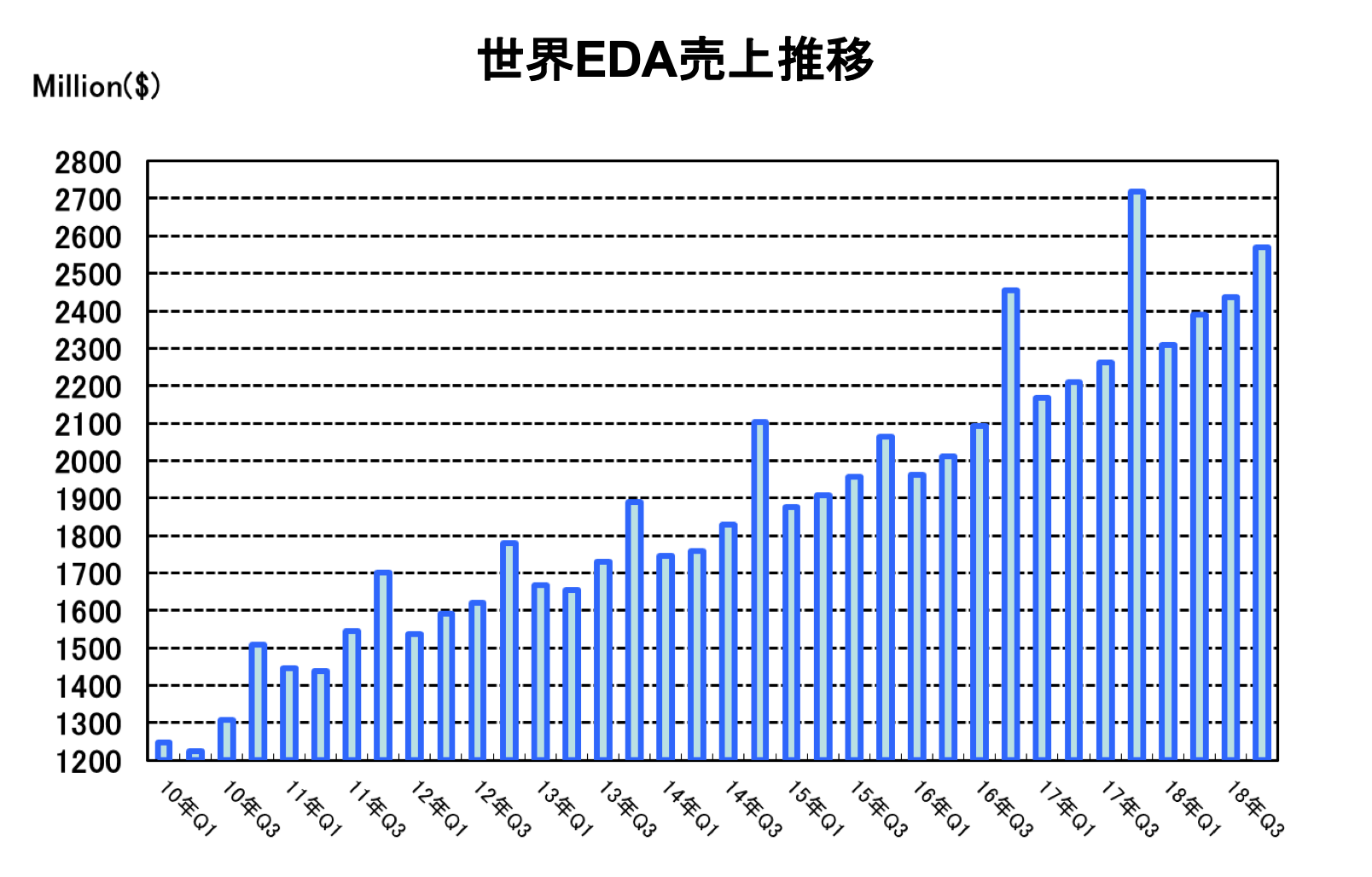
2019年4月15日、米ESD Allianceは、2018年度第4四半期(10月-12月)の世界EDA売上報告を発表した。
ESD Allianceの発表によると、2018年Q4(10-12月)の世界のEDA売上総額は前年比約3.1%減の25億7010万ドルで2015年Q4以降3年ぶりに前年実績を下回った。
2018年通年(Q1-Q4)の売上は、前年比3.7%増の97億430万ドルで9年連続の売上増を達成した。
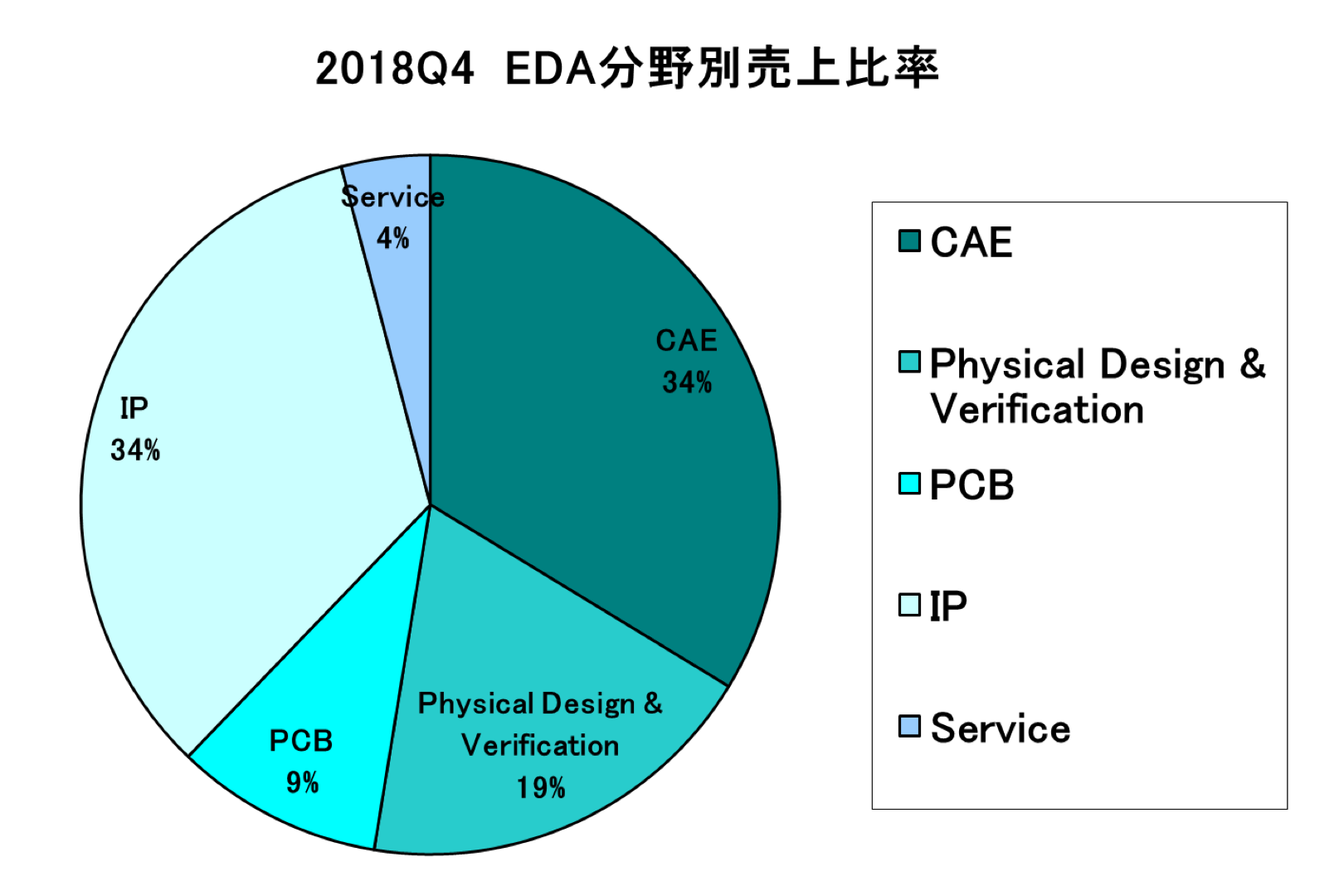
2018年Q4のEDA売上をカテゴリ別に見ると、主力のIP分野とIC Physical Design & Verification分野が大きく前年実績を割り込んだ。
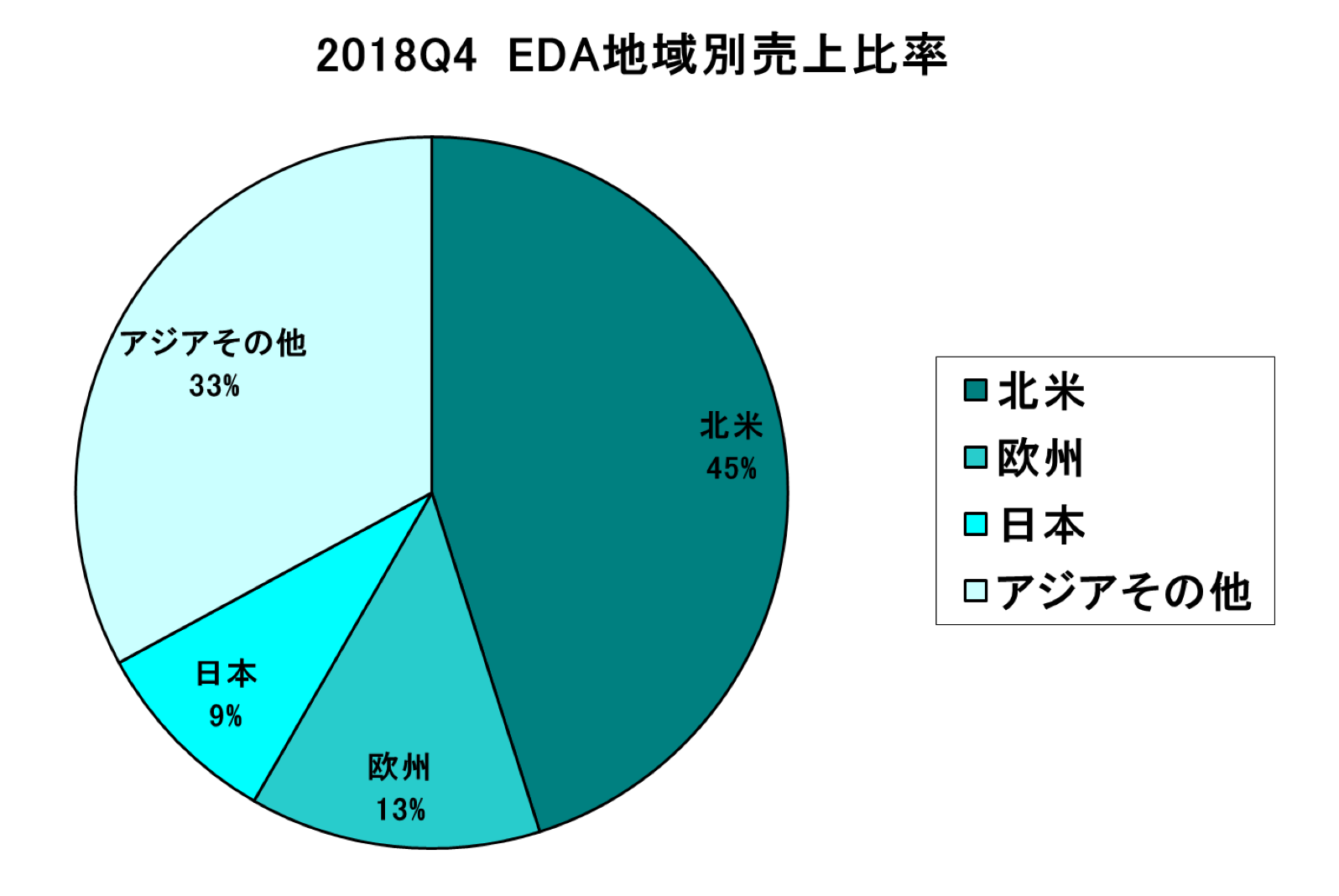
2018年Q4のEDA売上を地域別に見ると、全ての地域で前年実績を下回った。中でも北米、欧州は大きく落ち込んだ。
2018年Q4時点でのEDA業界の従業員数は前年比7.1%増の42,790人でQ3に続いて過去最高記録を更新した。
2018年Q4の分野別の売上と昨年同時期との比較は以下の通り。
■CAE分野 8億6620万ドル 2.4%Up
■IC Physical Design & Verification分野 4億8510万ドル 11.1%Down
■IP分野 8億6610万ドル 3.5%Down
■サービス分野 1億550万ドル 10.7%Down
■PCB/MCM分野 2億4730万ドル 2.6%Up
2018年Q4の地域別の売上と昨年同時期との比較は以下の通り。
■北米 11億5900万ドル 7.4%Down
■欧州 3億3980万ドル 12%Down
■日本 2億2500万ドル 1.7%Down
■アジアその他地域 8億4630万ドル 0.4%Down
※ESDA(Electronic System Design Alliance)
2019.04.19
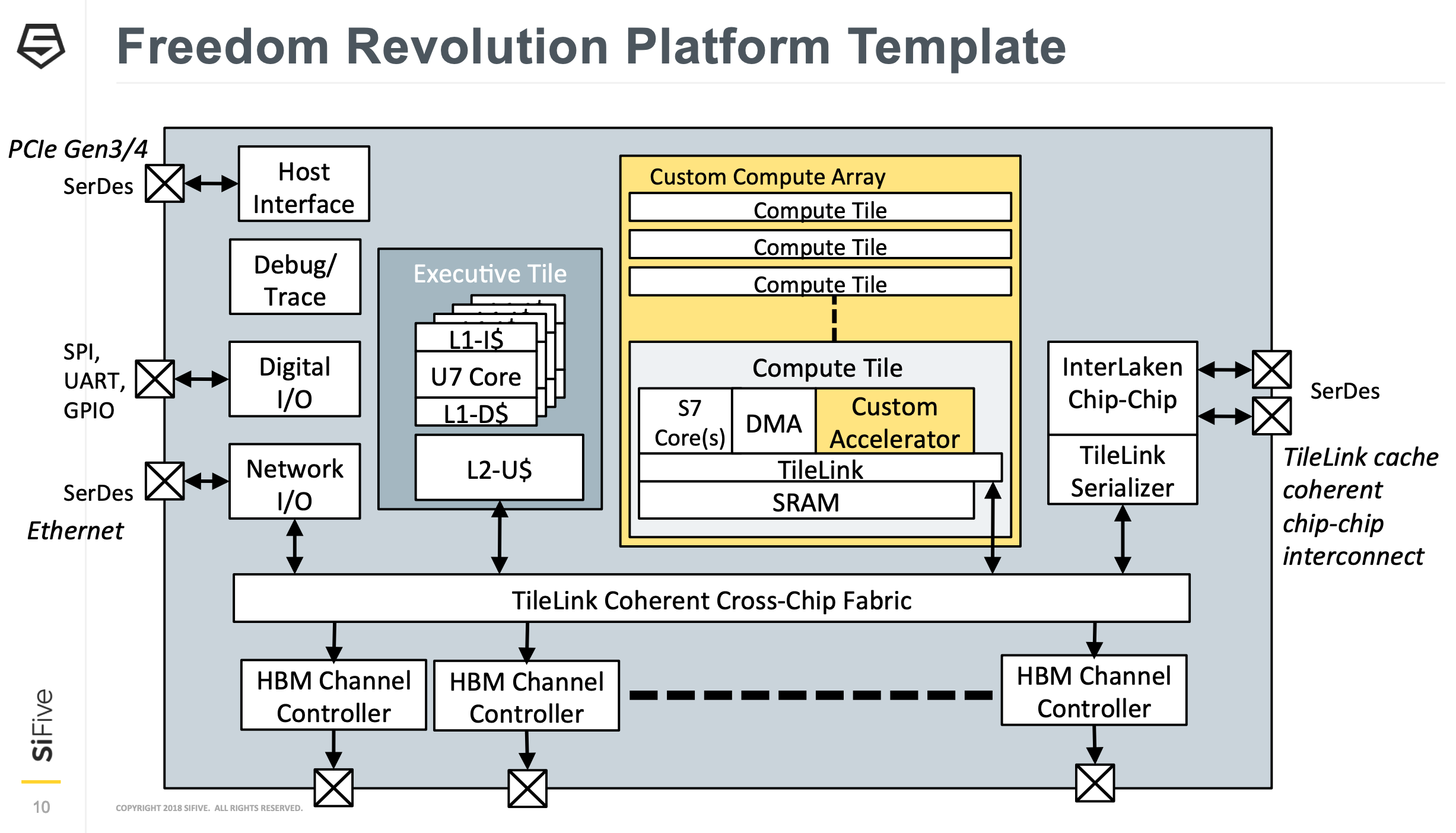
2019年4月11日、オープンソースのISA「RISC-V」ベースのプロセッサIPを手掛ける米SiFiveは、7nm対応のSoCプラットフォームのテープアウトを発表した。
「Freedom Revolution AI SoC Platform」と呼ばれるSiFiveの7nm向けSoCプラットフォームは、既存の16nmプラットフォームのアップグレード版で、vector extensionを備えた同社の64bitRISC-Vコア「U7」および「S7」をベースとした高性能プロセッサを核に下記の各種コンポーネントで構成される。
・キャッシュコヒーレント・ファブリック「TileLink」
・3.2Gb/s HBM2 controller&PHY
・2GHz TCAM(Ternary Content-Addressable Memory)IP ※パートナー製
・LVDSインタフェース
・PCIe5 SerDes, 56/112G SerDes
・セキュリティIP ※パートナー製
今回SiFiveがテープアウトを発表したカスタマイズ可能な7nm SoCプラットフォームは、AI、ネットワーキング、およびその他の高性能アプリケーションを主なターゲットとしているという。
※画像は現行の16nm向けの「Freedom Revolution Platform」のブロック図
2019.04.17
2019年4月16日、TSMCは新しい6nmプロセス(N6)を発表した。
発表されたTSMC N6プロセスは、EUVを利用するプロセスとしてN7+プロセスに次ぐTSMC第二のEUVプロセスで、EUVを利用しないN7プロセスと比較してロジック密度は18%向上する。デザインルールはN7テクノロジと完全に互換性があり、そのデザインエコシステムを再利用することが可能。N7プロセスからN6プロセスへシームレスに移行できる。
新しいN6プロセスは、2020年第1四半期からのリスク生産を予定。
2019.04.17
2019年4月16日、EETimesの記事:
IntelのFPGAグループはFPGA向けのコアを開発する英Omnitek社を買収した。買収に関する取引条件は開示されていない。Omnitekは従業員40名の会社で創業20年。放送やビデオ会議、医療など様々な市場向けに、ビデオ、ビジョン、その他のFPGA向けブロックを220種以上開発。直近の実績としては、XilinxのFPGA Ultrascale向けのディープラーニング推論ブロックの設計があり、現在Omnitekの開発した16種の製品がXilinxのFPGA上で稼働している。
Intelの担当者によると、今後Omnitekのチームは、IntelのFPGA用コアの開発とIntelのQuadricsおよびOpenVinoの使用にフォーカスするとの事。
2019.04.17
2019年4月16日、SamsungはEUVを用いた5nm FinFETプロセスの開発完了を発表した。
SamsungのEUVベースのプロセスは7nm, 6nm, に今回の5nmを加えて計3種類。開発を完了した5nm FinFETプロセスは既に顧客へのサンプル出荷が可能な状態で、PDK、デザイン・メソドロジ、EDAツール、IPといった5nm用のインフラは2018年Q4から提供されている。更に、Samsung Foundryは既に5nmマルチプロジェクト・ウエハ・サービスを顧客に提供し始めている。
Samsungによると7nmと比較して5nm FinFETプロセスは、消費電力が20%、パフォーマンスが10%向上し、ロジック領域の効率が最大25%向上。また、5nm FinFETプロセスでは7nmのIPを全て再利用することができるという。Samsungはこれにより、7nmから5nmへの移行が容易となり5nmの製品開発期間が短縮できるとしている。
Samsungは2018年10月に最初のEUV適用プロセスとなる7nmプロセスの準備と初期生産を発表し、今年初めに7nmプロセスの量産を開始。また、SamsungはカスタマイズされたEUVベースのプロセスである6nmプロセスで顧客と協力しており、既に最初の6nmチップの製品のテープアウトを受けている。
SamsungのEUVベースのプロセスは、現在韓国のHwaseongのS3ラインで製造されており、2019年後半には更にEUVのラインを増やして生産を開始する予定。
2019.04.16
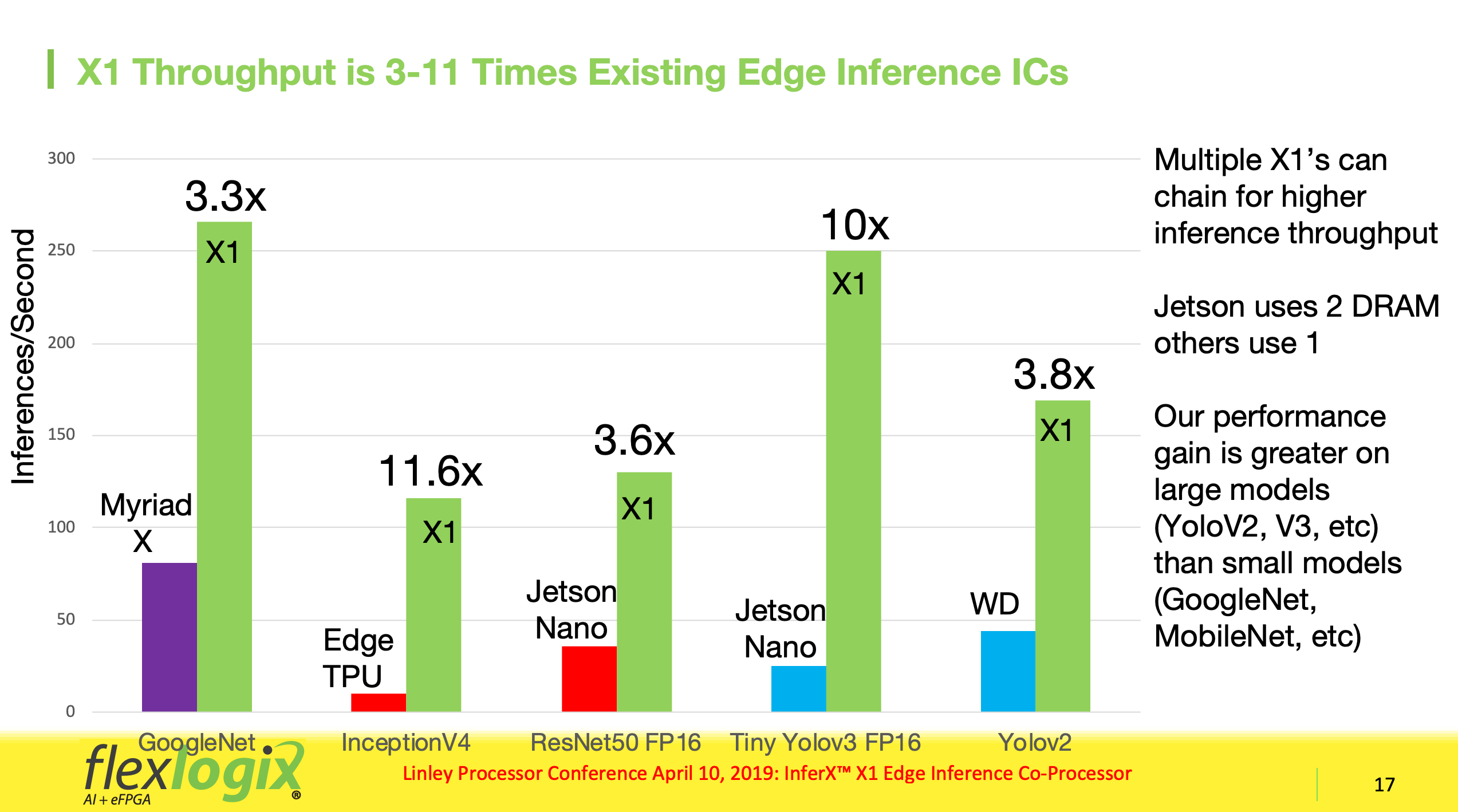
2019年4月10日、SoC組み込み型のFPGAコアを手掛けるFlex Logix Technologiesは、新製品となるエッジ推論向けのコプロセッサ「InferX X1」を発表した。
発表によると新製品「InferX X1」は、同社の組み込みFPGAで利用している特許取得済みのインターコネクト技術と、同社の推論向け組み込みFPGA「nnMAX」を組み合わせて実現したソリューションで、単一のDRAMでエッジの推論アプリケーションを高スループットかつ低電力で実行することが可能。Flex Logixはそのパフォーマンスを市販されているエッジ推論向けICの10倍以上と謳う。※「nnMAX」は1024個のMACとSRAMを搭載する組み込みFPGA IP
Flex Logixによると「InferX X1」は、エッジで扱われる小さなデータの処理に特に力を発揮し、小さいバッチサイズではデータセンターの推論ボード並のパフォーマンスを実現。1画像あたり何千億もの操作が必要な大規模推論モデルに最適化されており、例えばリアルタイム・オブジェクト認識「YOLOv3」の場合、2メガピクセルの画像を12.7フレーム/秒で処理できるという(DRAM1個)。
「InferX X1」は、エッジデバイス用チップとしてPCIeインタフェースのカードで提供される予定。チップ内部のアーキテクチャーはユーザーからは見えず、 Tensorflow Lite, ONNXモデルをサポートする専用コンパイラ「nnMAX Compiler」を使用してプログラムする。データ型はint8, int16, bfloat16をサポートし、それらを各レイヤで混在可能。一般的な畳み込み演算をint8モードに変換しスループットを倍以上に引き上げる「Winograd transformation」もサポートする。
Flex Logixは組み込みFPGAの分野で実績を伸ばしており、同社のIPを採用した顧客としては、MorningCore / Datang Telecom、DARPA、Boeing、Harvard、Sandia、SiFiveなどの名が挙げられている。
※Flex Logix Technologies
2019.04.16
2019年4月15日、DigiTimesの記事:
■Samsungとメモリ市場の動向
調査会社Gartnerによると、2018年半導体シェアトップのメモリ大手Samsungは、今年はランキング2位に落ちる可能性がある。
Samsungの半導体収益の88%がメモリの売上。世界半導体市場におけるメモリの売上は、2017年は前年比61.8%増だったが、2018年は前年比24.9%増に低下した。過剰供給により2018年Q4からDRAMの平均価格が下落し始めたが、それは2019年いっぱい続く見通し。
■世界半導体市場の動向
スマートフォン及びタブレット市場の低迷が続いていて、メモリに次いで売上の多いASSPの成長率が5.1%に留まっている。アプリケーションプロセッサ、モデム、その他のコンポーネントを販売するためにこれらのエンドマーケットに大きく依存している半導体ベンダーの大半は収益が減少している。QualcommやMediaTekなど同分野の大手は、自動車やIoTアプリケーションなど、成長の見込みがより強い隣接市場に積極的に拡大している。成熟したスマートフォン市場は、2019年も同分野への依存が高い企業にとって逆風となる可能性が高い。
2019.04.11
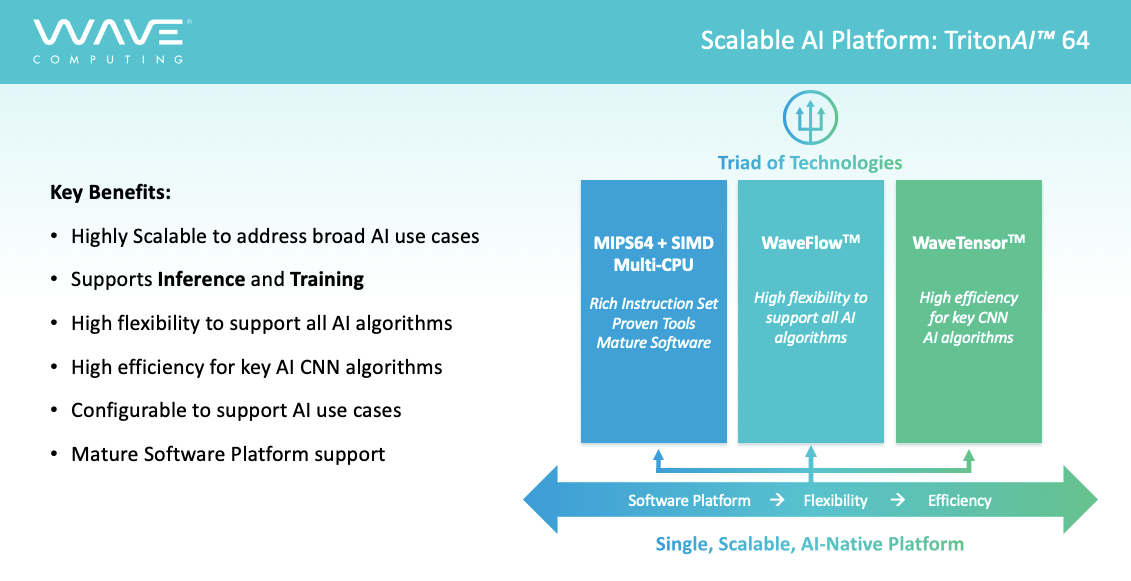
2019年4月10日、AIチップを手掛けるベンチャーWave Computingは、AI向けIPの新製品「TritonAI™ 64 platform」を発表した。
発表によると「TritonAI™ 64 platform」は、エッジAI市場をターゲットとしたスケーラブルかつプログラマブルなSoC向けのIPで、推論だけではなくトレーニングにも対応。現在はエッジでのAI推論を8-32ビットの整数ベースでサポートしており、今後エッジトレーニング向けにbfloat 16および32ビットの浮動小数点ベースのサポートを予定している。
Wave Computingによると「TritonAI™ 64 platform」のキーテクノロジーは3つ。
AIアプリケーション開発のためのソフトウェア・プラットフォームとなるのが「MIPS 64-bit+SIMDエンジン」で、SoC向けのサブシステムとしてMIPS 64ビットCPUを最大6個、それぞれ最大4個のハードウェアスレッドを利用可能。同MIPSサブシステムは、DebianベースのLinux OS上でGoogleのTensorFlowの実行をホストし、推論およびラーニングアプリケーション両方の開発を可能にする。また、Caffe2などの追加のAIフレームワークをMIPSサブシステムに移植したり、ONNX使用して様々なAIネットワークをサポートできる。
CNN向けに用意される「WaveTensor」サブシステムは、4×4または8×8カーネル行列乗算エンジンをスケーラブルに組み合わせる事で主要なCNNアルゴリズムを効率的に実行する事が可能。CNNの実行性能は、標準的な7nmプロセスで最大8TOPS/W、10TOPS/mm2以上を実現するとされている。
Wave Computing独自の特許技術による再構成可能なハードウェア・リソース「WaveFlow」は、柔軟かつスケーラブルであらゆる複雑なAIアルゴリズムに対応可能。「WaveFlow」サブシステムは、MIPSサブシステムのサポートを必要とせずにAIアルゴリズムを実行する事も可能でAIネットワークの同時実行もサポートする。
2019.04.10
2019年4月9日、ASICデザインサービスを手掛ける台湾のファブレス半導体ベンダFaraday Technologyは、RISC-VベースのASICプラットフォームを発表した。
発表によるとFaradayの提供するRISC-VベースのASICプラットフォームは、RISC-VベースのSoC開発を行う顧客向けのソリューションで、RISC-VコアIPの実装やSoCデザインの検証などのサービスに加え、RTOSやデバイスドライバで構成されるリファレンス・デザイン・キットも提供する。Faradayによると、同社は既に同プラットフォームを採用したRISC-VベースのAI向けおよびIoT向けSoCの量産を実現。IoT向けのSoCにおいてはバッテリー駆動の性能を高めることが出来たとしている。
いち早くデザインサービスとしてオープンソースの命令セット・アーキテクチャ「RISC-V」に対応したFaradayは、AI、IoT/AIoT、ネットワーキング等の多様なアプリケーションで、RISC-VベースASIC設計の商機が多くあると考えているようだ。
2019.04.10
2019年4月9日、DigiTimesの記事:
Digitimes Researchによると、Samsung Electronicsはサーバー向けDRAMチップの製造を2020年から新しい16nmプロセスへ移行する。
Samsungは世界のサーバー向けDRAM市場シェアの50%以上を保持。2018年半ばから18nmプロセス技術を使用した8Gbサーバー向けDRAMチップの量産を開始しており、2020年には16nmの16Gbチップへと出荷を拡大する予定。
Digitimes Researchによると、サーバーおよびデータセンターのアプリケーションは、2023年までにDRAMチップメーカーの最大のターゲット市場として、PCやモバイル機器に取って代わるようになるという。
2019.04.09
2019年3月27日、Mentor Graphicsは品川でプライベート・イベント「IESF 2019 Japan」を開催した。
IESF 2019 Japanは、車載システム開発にフォーカスした技術セミナーで、Mentorによるソリューション紹介と合わせて数々の顧客開発事例が発表された。
ここでは「AIチップ」開発に関するセッションとして行われた、「C++で先端大規模AIチップを開発−Mentorの高位合成ソリューション」について紹介する。
講演者はMentor GraphicsのCalypto製品事業部、山本修作氏である。
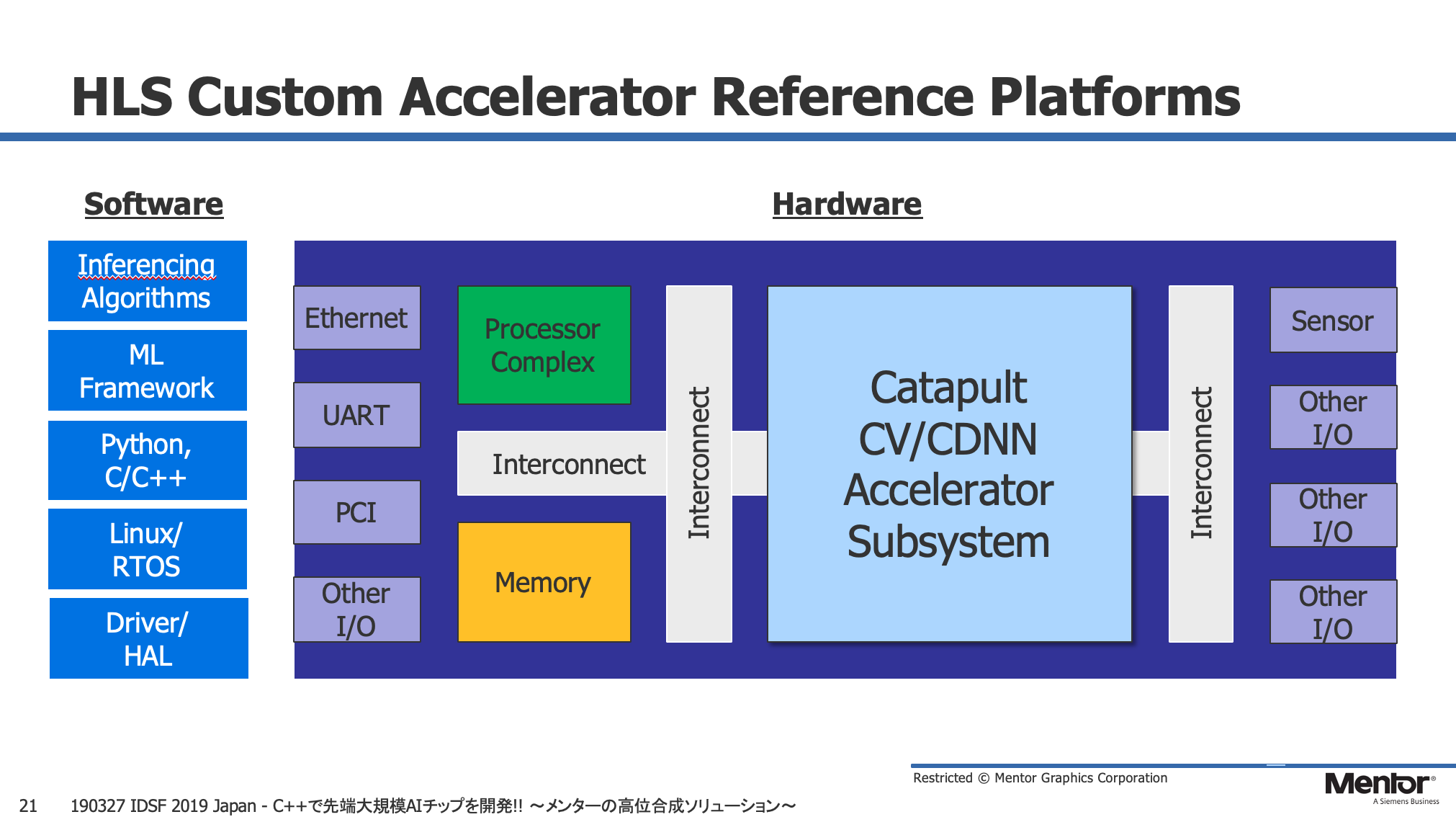
山本氏によると、Mentorの提供する高位合成ツール「Catapult」は、AIチップとしてはどちらかと言うとエッジ、端末向けのチップの開発をターゲットとしている。エッジ側のAIチップの多くは、面積、電力、性能(リアルタイム性)など、様々なアプリケーションの厳しい要求に応じるカスタム・ハードウェアであるため、その最適解をいち早く得る上で高位合成を用いた「CtoRTL」手法がはまるという。
特にAIチップの場合は複雑さが半端ではなく、仕様変更も頻繁、今後ますます複雑化していく事を考えると、限られた人員で従来ながらのRTL設計でAIチップを開発するのは困難。高位合成を使っても簡単に作れるものではないが、高位合成を使う事でAIチップの開発を大幅に効率化できると言うのが山本氏の基本的な主張だ。
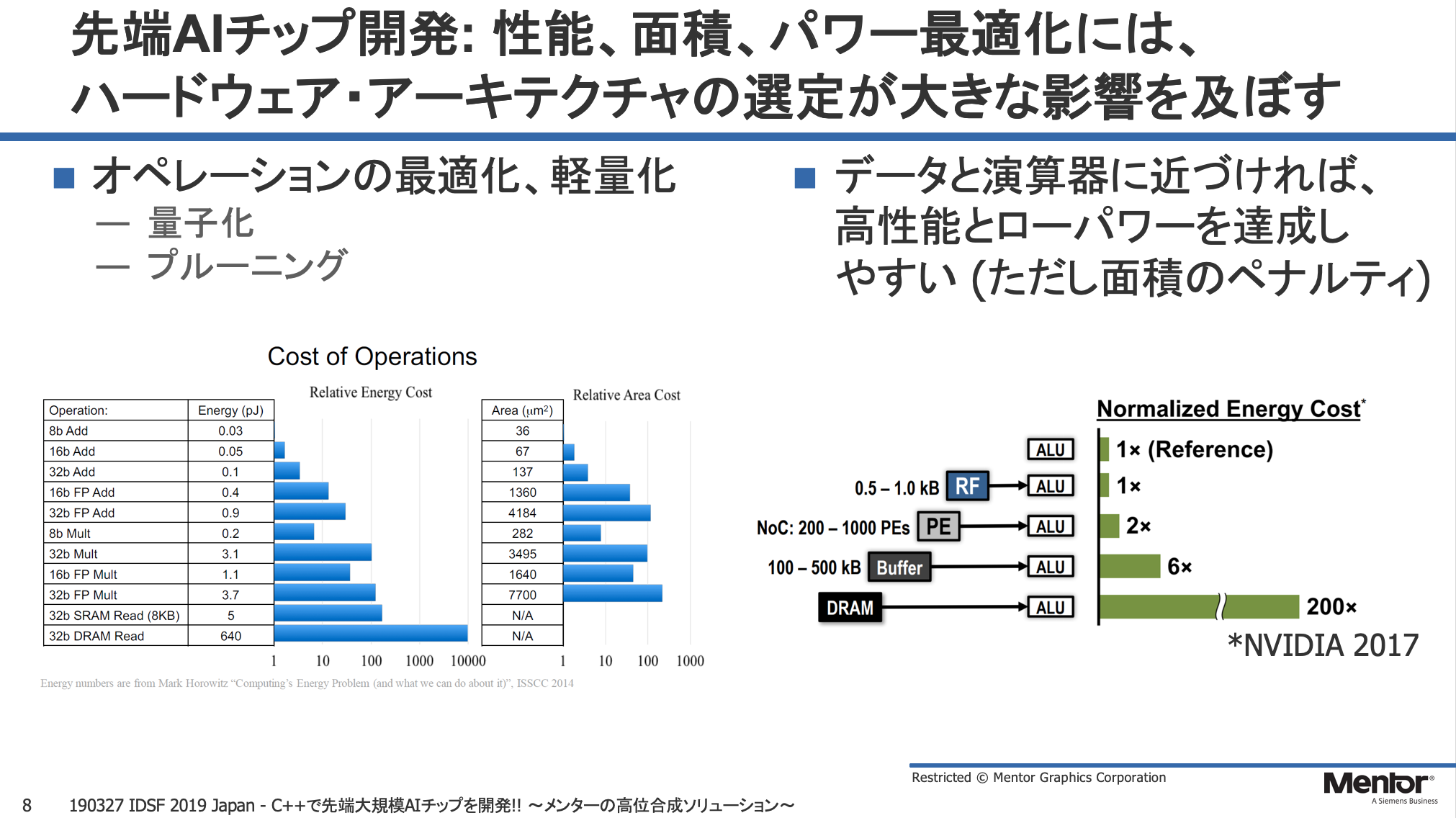
AIチップを開発する上での具体的なメリットとしてまず山本氏が挙げたのは、アーキテクチャの選定。山本氏によると、PPAの最適化に当たっては、量子化、プルーニングなどオペレーションの最適化も重要だが、ハードウェア実装面では演算器とデータの格納先の距離をいかに詰めるかがキー。例えば演算器とデータが近づけば演算スピードやクロック周波数を上げやすく消費電力も抑える事ができるが、その反面メモリによるチップ面積の増大によりチップコストが高くついてしまう。ニューラルネットの処理を考えると、演算性能を取るかメモリを取るかというバランスは非常に重要で、そのトレードオフにおいて高位合成が力を発揮すると山本氏は説明した。
性能、面積、コストのトレードオフという点は「Catapult」に限らず市販高位合成ツールの宣伝文句の定番だが、山本氏によると、Mentorの「Catapult」にはAI処理向けに使える独自のライブラリも用意されている。まず畳み込みニューラルネットワークの畳み込み層の部分は画像処理とほぼ同じで、「Catapult」で用意している画像処理系のIPを利用して設計できる。そのほかに代表的なものとしては、「ACデータタイプ」と呼ぶ任意のビット長に可変な独自のテータタイプや算術演算、線形代数のライブラリがあるほか、Google独自の浮動小数点数フォーマット「bfloat」もサポートしているという。また、「Catapult」のユーザーであるNVIDIAが「Catapult」向けに開発した、「Matchlib(Modular Approach To Circuits and Hardware Library)」というライブラリもあるとの話だ。(MatchilibはNVIDIAがGitHub上で公開 している。)
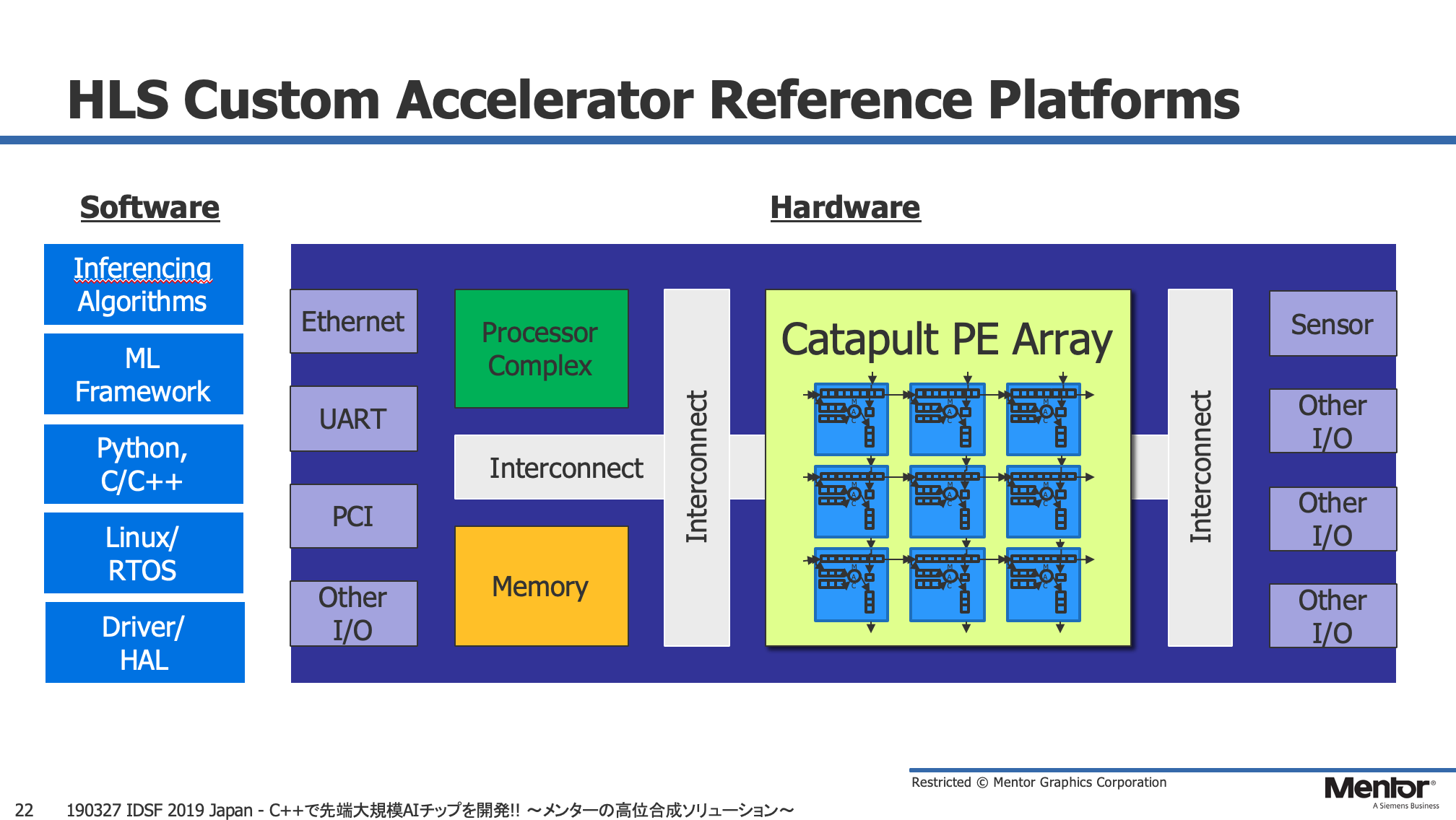
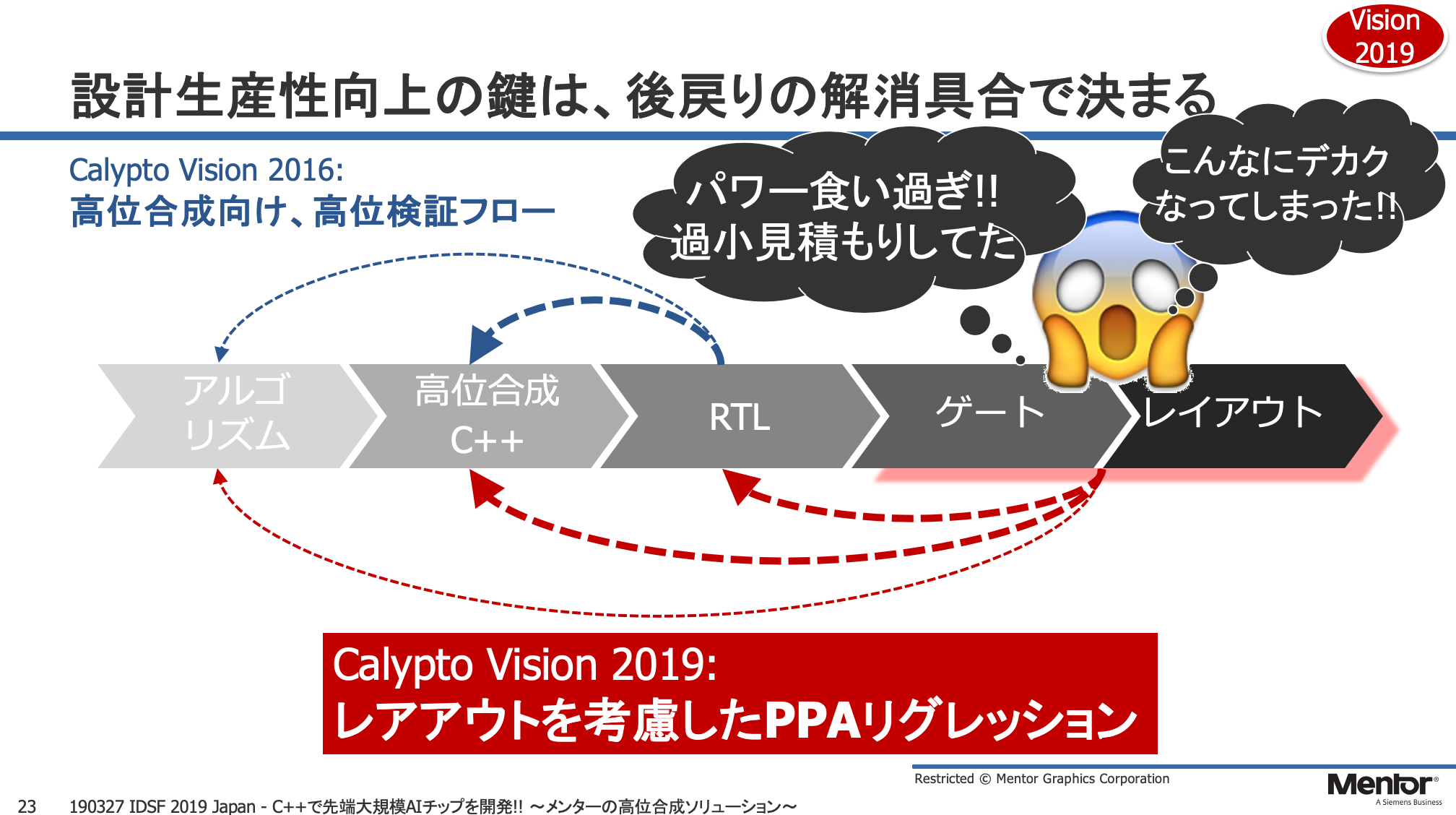
更に山本氏によると、Mentorは「Catapult」を用いたAIアクセラレータ開発用のリファレンス・プラットフォームの提供も計画中で、一般的なカスタムロジック実装向けとPEアレイを並べるタイプの実装向けの2種類のプラットフォームの用意を進めているという。また、「Catapult」の機能強化として、「設計の早い段階でレイアウトを考慮する事で設計の後戻りを解消する」というビジョンの下、PPAリグレッションを前倒しできるような機能を提供する計画との話。これにより従来出来なかったレイアウトを考慮したトレードオフが可能となり、Cのレベルでより詳細にデザインを最適化できるようになるという。
なお、同セッションで山本氏が紹介した「Catapult」を用いたAIチップの開発事例は下記の3つ。Chips&Mediaの事例についてはホワイトペーパーが公開されており、MentorのWebサイトからダウンロード可能との事。
1.FotoNation社
FotoNationはスマートフォン向けの顔認識IPを提供する会社で、IPの出荷実績は30億台以上。同社は次世代の顔認識IPを「Catapult」を用いて設計。Caffeでのニューラルネットワークの実装からFPGAでのハード化まで僅か3週間で完了。当初10fpsだった性能を「Catapult」を用いたアーキテクチャの最適化で30fps(100Mhz動作時)まで向上。RTL設計と比較して設計生産性は4倍、ASIC化に向けたRTLの最適化も容易に完了できた。
2.Chips&Media社
韓国のIPベンダChips&Mediaは、DNN+Deep Learningによる4K/30fpsリアルタイム物体検知IPを「Catapult」を用いて設計。アルゴリズム記述から合成可能なCへの変換を容易に済ませ、工数を掛けずに複数のアーキテクチャを試しPPAを最適化。開発終盤での仕様変更にも容易に対応でき、設計/検証期間を大幅に短縮した。
3.DARPA
DARPA(アメリカ国防高等研究計画局)は、チップ設計の高速化プロジェクト(従来RTL手法の10倍を目指す)においてNVIDIAの提案する高位合成とIPを用いた設計手法を採用。実際にNVIDIAの開発した高位合成用のIP「Matchlib」と「Catapult」を用いて2品種のAIアクセラレータチップを設計。うち1品種はPEアレイを並べるタイプのAIアクセラレータで開発の95%は「Catapult」を利用。従来のRTL設計を行ったのはチップ全体の僅か5%だった。
なお山本氏は、「Catapult」を用いた設計生産性向上の鍵となるのは「高位の検証手法」である事を強調。「Catapult」にはそのための検証環境「Catapult DesignChecker」および「Catapult Coverage (CCOV)」が用意されており、RTLではなくCのレベルで機能検証を完了する事が可能。更にその高位の検証環境を利用してRTLでのサインオフ検証を容易に行う環境「SCVerify」、「SLEC HLS」も整えられている。このような強力な検証環境は業界唯一であり、これによって高位合成の能力を最大限引き出せると山本氏は自負していたが、実際に検証はCで閉じて出てきたRTLはワンパスでチェックという手法は「Catapult」ユーザーに高く評価されているという事だ。
※画像は全てMentor Graphics提供のデータ
今回のセッションは時間の関係もあり概要的な説明に終始したが、Mentorは「Catapult」を用いたAIアクセラレータの開発にフォーカスしたセミナー「Mentor AIセミナー 」の開催を予定している。(4/16,17と2回開催)同セミナーでは「Catapult」を用いた実践的な設計手法の詳細が紹介される予定。
2019.04.06
2019年4月1日、シリコンバレーのAIチップスタートアップSambaNova Systemsは、資金調達Bラウンドの成功を発表した。
発表によるとSambaNovaの資金調達Bラウンドの調達額は1億5000万ドルで、新たに同社の投資に加わったIntelキャピタルが主導し、既存の投資家であるGV(旧Google Ventures)、Walden Internationalらがこれに続いた。
SambaNovaは昨年3月に資金調達Aラウンドで5600万ドルを調達しており、同社の累計調達額は2億ドルを超えた。SambaNovaの開発するAIチップについてはあまり情報が公開されていないが、ソフトウェア定義型のハードウェアと表現される彼らのチップは柔軟で効率的かつスケーラブルで、アルゴリズムからシリコンへのデータフローに最適化されたシステムアーキテクチャを実現しているとの事。投資したGVの担当者はSambaNovaのAIチップを「絶えず進化するソフトウェアの進歩(AI、ニューラルネット、ディープラーニングなど)をリアルタイムで活用してハードウェア性能をさらに最大化できる。」と表現している。
なおSambaNovaの開発するAIチップはサーバー向けと推測されていたが、昨年の9月以降のプレスリリースでは「データセンターからエッジまでのAIプラットフォーム」と明言しており、今回の発表では追加の資金調達に伴い製品ロードマップと製品機能の範囲を拡大するとしている。
SambaNovaのバックグラウンドについては下記関連ニュース参照
2019.04.05
2019年4月1日、カナダのAIチップスタートアップUntether AIは、資金調達Aラウンドの成功を発表した。
Untether AIはカナダのトロントに本拠を置く2018年設立のAIチップスタートアップで、ディープラーニング推論用のチップを開発している。ファウンダー3人のうち2人はトロント大学の出身、これまでにチップビジネスに関わってきた経験があり、市場投入したチップの数は10億個以上との事。
同社の開発している推論チップは、演算ユニットとメモリ間のデータ転送のボトルネックを解消する「processing-near-memory architecture」により、一般的なアーキテクチャの1,000倍に当たる毎秒2.5ペタビットという速度でデータをプロセッサに転送可能。バスを使ってデータをプロセッサに転送するコストを完全に無くし消費電力を大幅に削減できるため、推論効率を劇的に向上できるという。
今回、Intel Capitalをはじめとする投資家から計1300万ドルを調達しステルスモードから脱したUntether AIは、既にプロトタイプを完了している「エネルギー効率が最も高いAIアクセラレータ」の市場投入を目指す。
2019.04.04
2019年4月3日、TSMCは5nmプロセス向けの設計インフラの整備完了を発表した。
TSMCの5nmプロセス向けの設計インフラとして用意されるのは、5nm デザイン・ルール・マニュアル(DRM)、SPICEモデル、プロセス・デザイン・キット(PDK)、シリコン検証済みのファンデーションおよびインタフェースIP、認定EDAツールによってサポートされる設計フローなど。これらはTSMCおよびTSMC Open Innovation Platformのエコシステム・パートナーによって整備されている。
TSMCによると5nmプロセスは既にリスク生産を開始しており、2020年からの量産開始を計画中。EUVを用いるTSMCの5nmプロセスは7nmプロセスと比較して、ARM Cortex-A72コアで1.8倍のロジック密度と15%の速度向上を実現。そのプロセス・アーキテクチャによってSRAMおよびアナログ領域の実装面積を削減可能で、EUV適用により歩留まり向上効果も得られるという。
2019.04.03
2019年3月25日、フランスのプロセッサIPベンダCortusは、同社初となるRISC-Vベースのプロセッサ・ファミリの一般提供を発表した。
今回Cortusが発表したRISC-Vベースのプロセッサ・コアは下記の6品種。
・APS1V(RV32EMC)小面積、超低電力の32ビットCPU
・APS3V(RV32IMC)低電力でAPS3Vより高性能な32ビットCPU
・APS5V(RV32IMAC)マルチコア向け32ビットCPU
・FPS6V(RV32IMACF)単精度浮動小数点をサポートする32ビットCPU
・FPS8V(RV32GC)倍精度浮動小数点をサポートする32ビットCPU
・FPS69V(RV64GC)倍精度浮動小数点とMMUをサポートする64ビットCPU
CortusはArmの置き換えを狙った独自の低価格ISAベースコアを提供しており、それらコアの出荷実績は40億台を超える。2017年からはRISC-V Foundationにプラチナメンバーとして加盟していた。
Cortusによると、今回発表したRISC-Vベースのプロセッサ・コアは、すでに航空宇宙、衛星、産業、自動車の各分野の顧客プロジェクトで利用されているという話。Cortusのプロセッサ・コアのユーザーは、グラフィカルな開発環境、コンパイラ、デバッガ、RTOSなど開発エコシステムを利用できる。
2019.04.03
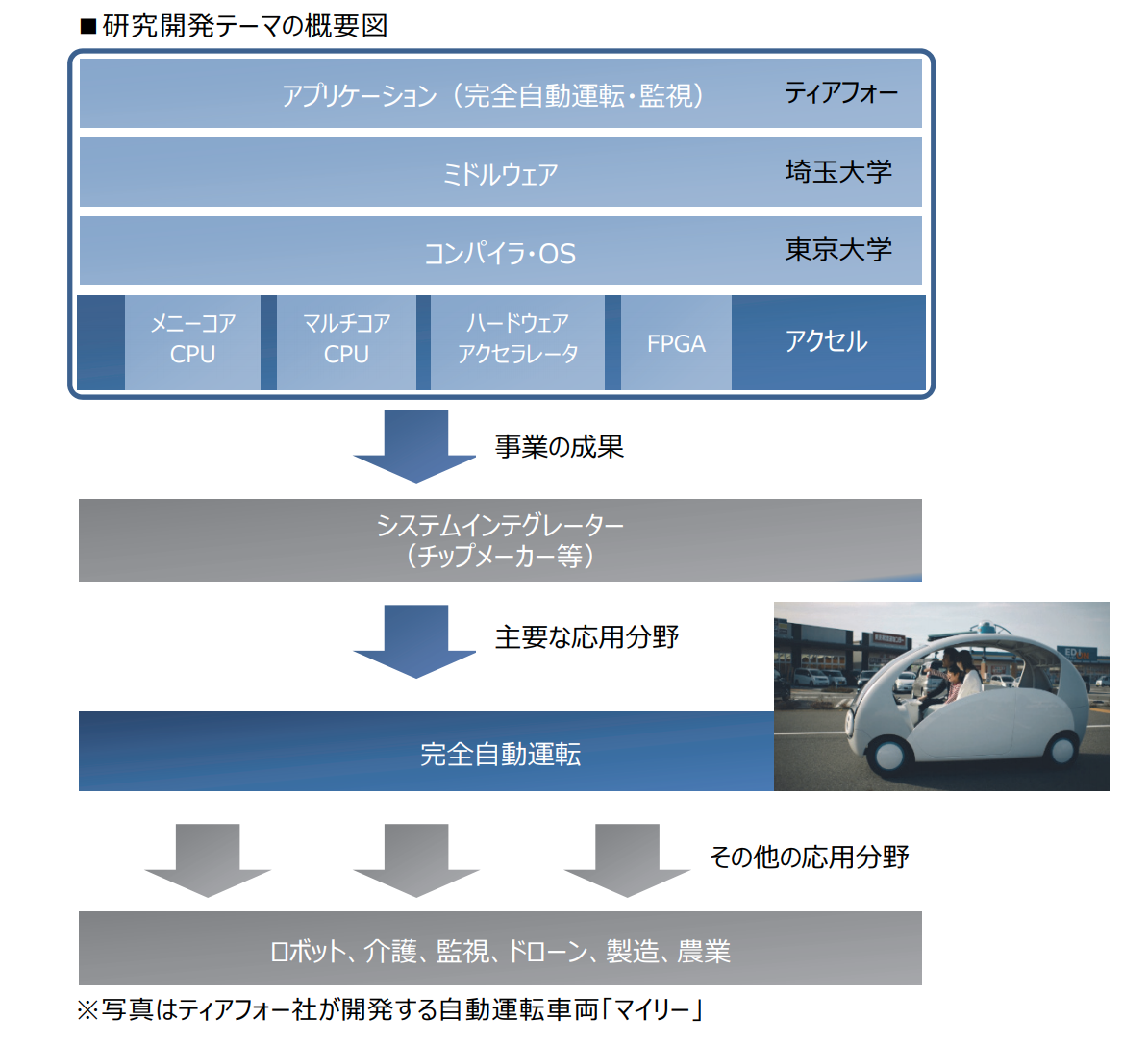
2019年3月29日、グラフィックスLSIを手掛けるアクセルは、NEDOの公募事業に採択された事を発表した。
発表によるとアクセルが採択されたのは、NEDOの「高効率・高速処理を可能とする AIチップ・次世代コンピューティングの技術開発」事業の研究開発項目「革新的 AI エッジコンピューティン
グ技術の開発」で、「完全自動運転に向けたシステムオンチップとソフトウェアプラットフォームの研究開発」を東京大学・埼玉大学・株式会社ティアフォーと共同で進める。
※画像はプレスリリース掲載の画像データ
アクセルによると、今回NEDO事業に採択された研究開発テーマでは、完全自動運転に向けたSoCとソフトウェア・プラットフォームの研究開発により、AIエッジコンピューティングにおけるリアルタイム性の実現と従来比10倍以上の消費電力対性能の達成を目標にしており、アクセルは完全自動運転に特化した独自のアクセラレータ及びメニーコア混在のヘテロジニアスSoCの研究開発を主に担当。2021年度をめどに試作チップの完成を目指す。
2019.04.03
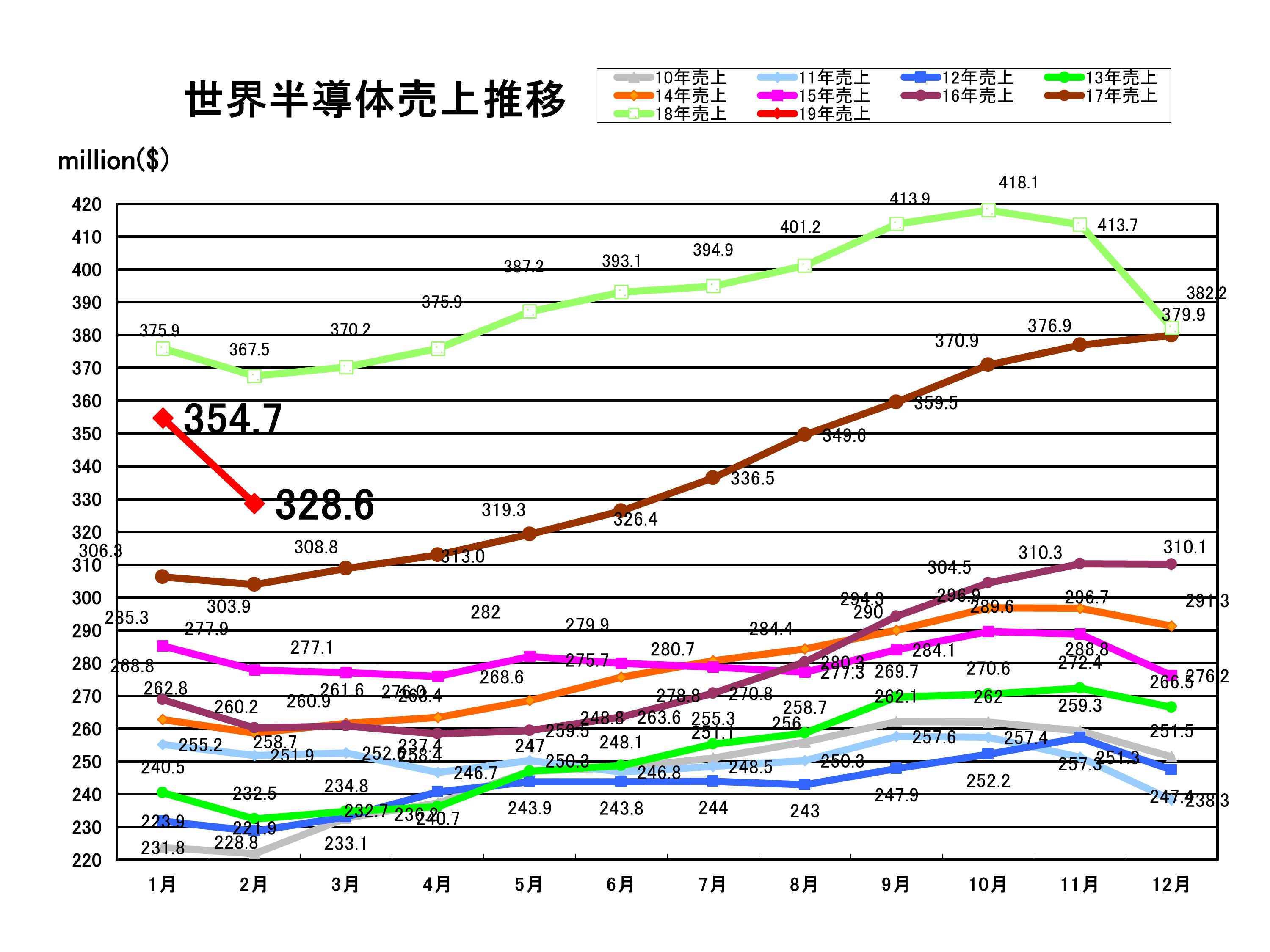
2019年4月2日、米SIA(Semiconductor Industry Association)は、2019年2月の世界半導体売上(3ヶ月移動平均)を発表した。
SIAの報告によると、2019年2月の世界半導体売上は前年同月比10.6%減、前月比7.3%減の328.5億ドルだった。1月に2年半振りに前年実績を割り込んだが、2月は更に売上が落ち込む形となった。これで2018年11月以降4ヶ月連続で売上が減少している。
2019年2月の売上を地域別で見ると、全ての地域で1月の実績および前年実績を下回った。最も売上が落ち込んでいるのは北米市場で前年比22.9%減。9-11月と12-2月の売上平均を比較すると直近は33.6%も売上が落ちている。
日本市場の2月の売上は前月比5.3%減、前年比5.9%減の29.9億ドル。売上を円ベースで換算すると前年比約3.8%減の約3299億円となる。
なお、今年に入って発表された各社、各団体の世界半導体市場予測を見ると、メモリの業績悪化に伴いマイナス成長の予測が増えてきている。
2019.04.02
2019年3月20日、Synopsysは同社の提供するインプリ環境「Fusion Design Platform」による7nmデザインのテープアウト実績について発表した。
Synopsysによると、同社の配置配線ツール「IC Compiler™?」や「Fusion Compiler」を核とするインプリ環境「Fusion Design Platform」を用いた7nmデザインのテープアウト実績が100件を超えたとの事。
現在7nmチップを製造できるのはTSMCとSamsungの2社のみで、いずれもこの1年以内に量産を開始したばかり。100件以上というテープアウト実績もこの1年の話だという。
Synopsysの「Fusion Design Platform」は、単一データモデルの共有をはじめとするツール間の密接な連携がうり。これにより複数ベンダのツールを繋げる従来フローよりも高品質な結果を短い開発期間で手に入れる事ができる。Synopsysによると「Fusion Design Platform」の採用数は急増中でルネサス エレクトロニクスもその採用ユーザーの1社(関連プレスリリース)。同インプリ環境を用いる事で難易度の高いデザインの設計結果品質を20%、開発スピードを2倍向上できるという。
2019.04.02
2019年4月1日、Cadenceは同社のツールがSamsung Foundry最新のGAA(gate-all-around)FET技術に対応した事を発表した。
プレスリリース
発表によると、Cadenceの配置配線ツール「Innovus™」と寄生抽出ツール「Quantus™」がSamsung最新のGAAFET技術に対応し、EUVを使いたGAAFETプロセス開発向けのテストチップのテープアウトを成功させた。Synopsysは一足早く同種の発表を行なっている。(関連ニュース )
なお、話は少し逸れるが、同じく4月1日にEDA業界のWebメディア「DeepChip」に興味深い記事 が掲載された。
どうやらCadenceは大口顧客Intelから大型契約を獲得した模様。
その契約額は年間1億ドル以上の3年契約で配置配線ツール、論理シミュレータ、エミュレーション・システムが対象との憶測もあるようだが、実際に大口顧客がIntelかどうかは定かではない。
2019.04.02
2019年3月28日、Mentor Graphicsは、ダイキン工業によるPCB設計プラットフォーム「Xpedition」の採用事例を発表した。
発表によるとダイキン工業は、Mentorの提供するPCB設計プラットフォーム「Xpedition」を世界各地の開発拠点におけるグローバルな設計環境プラットフォームとして採用。ダイキンは他社のツールでPCB設計プロセスを確立していたが、設計効率と品質の更なる向上を目指しMentorの「Xpedition」を選んだ。最大のモチベーションは分散する開発拠点間におけるCADライブラリと設計データの共有で、ダイキンは「Xpedition」の提供する一元化された強力な設計データ管理とコラボレーション機能を高く評価し採用を決定したと言う。
2019.03.29
2019年3月28日、Wave Computingは32ビットおよび64ビットのMIPS命令セットアーキテクチャ(ISA)の最新バージョンR6の無償公開を発表した。
MIPS ISAの最新バージョンR6は、https://www.mipsopen.com/ よりダウンロード可能。「MIPS Open program」に登録すれば、ライセンス料やロイヤリティを支払う事なく無償でMIPS ISAバージョンR6にフルアクセスできる。またWave Computingは、MIPS ISAと合わせてMIPSオープン・コンポーネントとして以下も無償公開している。
・MIPS ISA:MIPS 32ビットおよび64ビットアーキテクチャの最新バージョンR6
仮想化、マルチスレッド、SIMD、DSP、microMIPSコード圧縮などの拡張機能が含まれる
・MIPS Open Tools:MIPSベースシステムの統合開発環境
・MIPS Open FPGA:FPGAを用いたMIPSの学習・評価用パッケージ
ハンズオン・トレーニングやチュートリアル、MIPS microAptiv coreの非商用Verilog-RTLコードなどが含まれる ※MIPS Open FPGAはIntel(Altera)およびXilinxのボードに対応
MIPSオープン・コンポーネントは今後も機能追加や機能強化が計画されており、MIPS microAptivコア向けの商用RTLコードもリリースされる予定。
Wave Computingは、MIPS Openプログラムのイベント「MIPS Open Developer Days」を開催する予定だという。
MIPS Openプログラムに関する詳細は、https://www.mipsopen.com/ を参照


















{kind=link}