



生成AIを用いたチップ設計の新ベンチマーク「ChipBench」が指摘する実務レベルの課題
2026年1月29日、UCSD(University of California San Diego)およびコロンビア大学の研究者らが下記タイトルの論文を発表した。
「ChipBench: A Next-Step Benchmark for Evaluating LLM Performance in AI-Aided Chip Design」
同論文は、LLMを用いたチップ設計のための包括的なベンチマーク「ChipBench」を提案するもので、LLMを実務レベルで利用する際の貴重な示唆を与えてくれる。
詳細については論文を参照頂きたいが、ポイントを簡単にまとめてみよう。
背景:
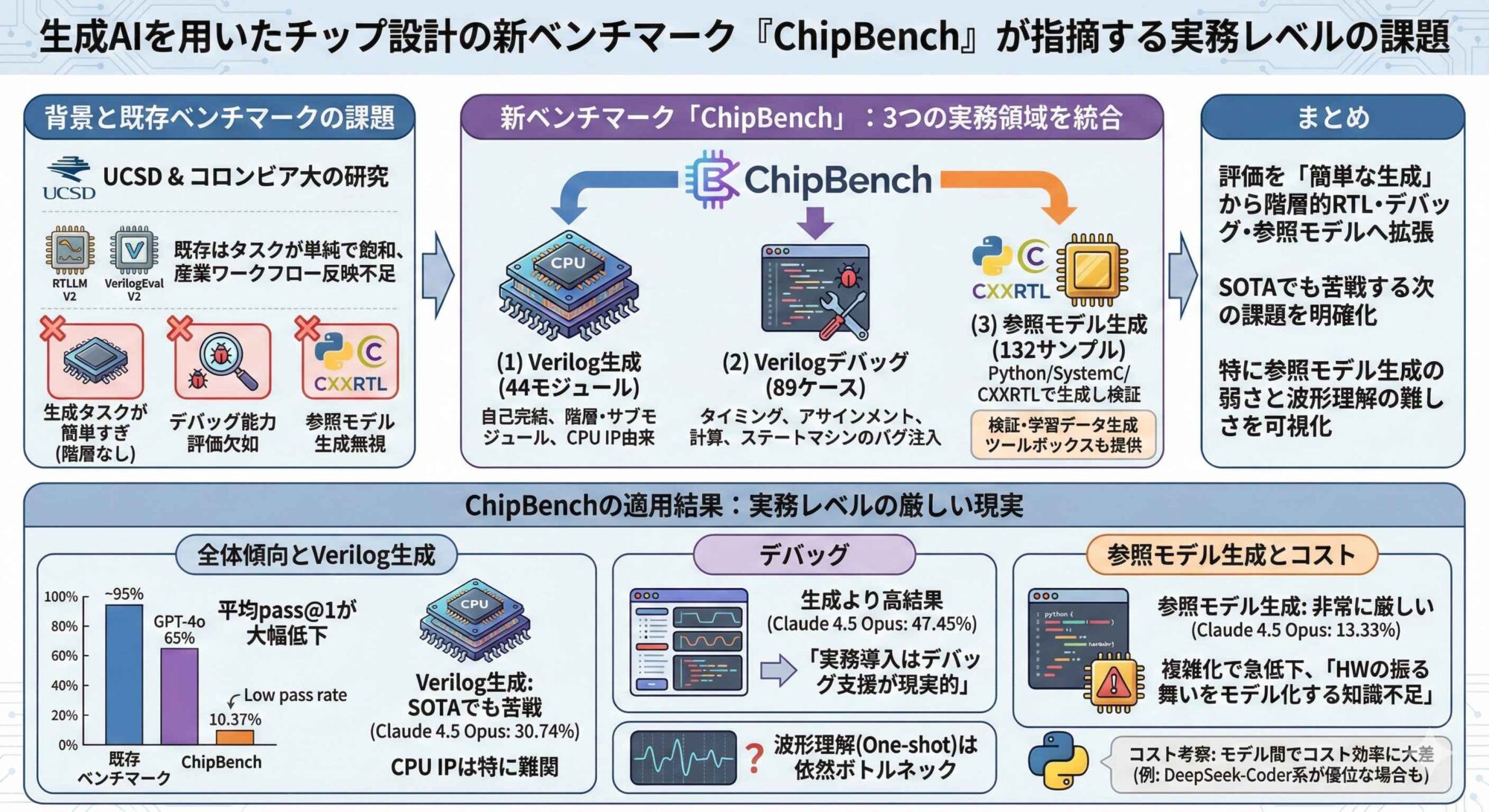
RTLLM V2、VerilogEval V2といった既存のVerilog生成ベンチマークはタスクが単純で“飽和”しつつあり、産業的ワークフローを十分に反映できていないため、より実務に近い形でLLMの実力を測るための包括的ベンチマークが必要。
論文で提案する「ChipBench」は、評価対象を「生成」だけに限定せず、実務で重要度が高い (1) Verilog生成、(2) Verilogデバッグ、(3) 参照モデル(reference model)生成の3領域をまとめて扱う。
既存ベンチマークの課題:
- 生成タスクが簡単すぎる
既存ベンチマークは短く自己完結のモジュールが中心で、階層設計やサブモジュール連携が少ない。実務のVerilogは階層的・大規模になりがちで、ギャップが大きい。 - デバッグ能力の評価が欠けている
実務では最初から完全正解のRTL生成よりも、既存コードの修正・デバッグ支援の方がLLMを導入しやすいのに、デバッグ能力に関する評価が手薄。 - リファレンス・モデル生成が無視されてきた
検証工程で使うリファレンス・モデル(Python/SystemC/CXXRTL等)の生成は重要だが、既存のベンチマークでは評価の対象外だった。
ChipBenchの中身(タスク設計):ChipBenchは合計264+ケースを提供
・Verilog生成(44モジュール)
自己完結型に加え、非自己完結(階層・サブモジュール)や、CPU IP由来のより実戦的なサブモジュールも含める構成。
・Verilogデバッグ(89ケース)
タイミング・バグ、アサインメント・バグ、計算バグ、ステートマシン・バグの4系統のバグを体系的に注入した修正タスク。
・リファレンス・モデル生成(132サンプル=44×3言語)
Python、SystemC、CXXRTL(C++)でリファレンス・モデルを生成し、ゴールデンVerilogと突合して検証できる枠組み。
さらに、リファレンス・モデル生成を研究しやすくするため、参照モデルの検証と学習データ生成のツールボックスも提供する。
ChipBenchの適用結果:
複数のLLMで評価し、既存ベンチマークでは高い通過率が出る一方、ChipBenchでは平均pass@1(1回の生成による正答率)が大きく低下する点を強調する。たとえばGPT-4oはRTLLM V2やVerilogEval V2で約65%のpass@1を示す一方、ChipBenchでは10.37%に落ちたという。
-Verilog生成
Verilog生成では、Claude 4.5 Opusの平均pass@1が30.74%、マルチエージェントのMAGE(DeepSeek-V3)でも37.41%に留まった。これらLLMは既存のベンチマークでは95%超という結果がでるという。
また、CPU IPは特に難しく、pass@1が伸びにくい傾向となった。
-デバッグ
デバッグでは、Claude 4.5 Opusの平均pass@1が47.45%で、同一モジュールの生成(30.74%)よりも高い結果となった。この差から、「実務導入は生成よりデバッグ支援が現実的」という方向性を支持する。
一方、VCD波形を与えるOne-shotデバッグは、改善するモデルもあるが悪化するモデルも多く、「波形を解釈して修正に結び付ける能力」が依然ボトルネックだと示唆する。
-リファレンス・モデル生成
参照モデル生成(Python)では、Claude 4.5 Opusの平均pass@1が13.33%、近い水準のモデルでも概ね1~2割台に留まると厳しい結果に。単純な自己完結モジュールでは相対的に通るものの、複雑化すると急速に難しくなり「Pythonは一般タスクで強いのに、ハードウェアの振る舞いを正しくモデル化する知識が不足している」という問題を指摘。
コストに関する考察:
トークン量・費用・Cost/Pass@1をまとめ、同等精度でもモデル間でAPIコストが大きく異なる点を指摘。例えば、Claude 4.5 Opusはpass@1が高めでDeepSeek-Coder系がコスト効率で優位になり得る。
まとめ:
ChipBenchは、LLM×チップ設計の評価を「簡単なVerilog生成」から、階層的RTL・デバッグ・参照モデル生成へ拡張し、SOTAでも苦戦する次の課題を明確にしたベンチマーク。特に、リファレンス・モデル生成の弱さと、波形を使ったデバッグ理解の難しさを、数字とワークフロー込みで可視化した点が実務・研究の両方に効く。

= EDA EXPRESS 菰田 浩 =
(2026.02.03
)